In 1959, John McCarthy was building Lisp at MIT when he encountered a problem that would define decades of programming language design. Programs in Lisp created and destroyed linked structures constantly—lists within lists, functions returning functions, recursive structures that no programmer could feasibly track manually. McCarthy’s solution was to make memory management automatic. He called it “garbage collection,” dedicating just over a page in his seminal paper to describe a mark-and-sweep algorithm that would free programmers from the burden of explicit deallocation.
Sixty-five years later, garbage collection has evolved from a theoretical curiosity into one of the most sophisticated components of modern runtime systems. The journey from McCarthy’s original design to today’s sub-millisecond concurrent collectors reveals a fascinating interplay of algorithms, hardware evolution, and practical engineering trade-offs that every developer should understand.
The Fundamental Problem: Why Manual Memory Management Fails
Before diving into how garbage collection works, it’s worth understanding why it exists at all. Manual memory management—where programmers explicitly allocate and free memory—seems straightforward in principle. A program requests memory, uses it, and returns it when done. But this apparent simplicity masks three categories of bugs that have caused countless security vulnerabilities and crashes:
Dangling pointers occur when memory is freed while references to it still exist. The freed memory might be reallocated for a different purpose, and subsequent access through the old pointer corrupts data in unpredictable ways.
Double-free bugs happen when the same memory region is freed multiple times. Memory allocators maintain complex internal data structures, and freeing the same block twice corrupts these structures, often leading to crashes or exploitable vulnerabilities.
Memory leaks emerge when allocated memory is never freed despite becoming unreachable. Programs that leak memory eventually exhaust available resources, a particularly critical concern for long-running server processes.
A landmark 2005 study by Hertz and Berger quantified these issues. They found that even experienced programmers make memory management errors at a rate that compounds significantly in large codebases. Garbage collection eliminates entire categories of these bugs by automatically identifying and reclaiming memory that can no longer be accessed.
The Two Fundamental Approaches
All garbage collection algorithms fall into two broad categories: reference counting and tracing. Each approach has distinct characteristics that make it suitable for different scenarios.
Reference Counting: Immediate but Limited
Reference counting maintains a counter for each object tracking how many references point to it. When a reference is created, the counter increments; when a reference is destroyed, the counter decrements. When the counter reaches zero, the object is immediately reclaimed.
The elegance of reference counting lies in its simplicity and determinism. Objects are reclaimed precisely when they become unreachable, with no delay. This makes reference counting particularly suitable for resource management where timely cleanup matters—file handles, network connections, and other system resources.
However, reference counting suffers from a fatal flaw: cyclic references. Consider two objects that reference each other:
Object A → Object B → Object A
Even if both objects become unreachable from the rest of the program, their reference counts never reach zero because they hold references to each other. This creates a memory leak that the basic algorithm cannot detect.
Modern implementations address this limitation through cycle detection algorithms. Python, for instance, uses reference counting as its primary mechanism but supplements it with a generational cycle detector that periodically identifies and breaks reference cycles. The cycle detector maintains separate generations (typically three: 0, 1, and 2) and performs collection based on thresholds that balance memory efficiency against CPU overhead.
Reference counting also incurs overhead on every assignment operation. In multithreaded environments, these increments and decrements must be atomic operations, adding synchronization costs. Research by Levanoni and Petrank demonstrated that update coalescing—batching multiple reference count updates—can eliminate over 99% of counter updates in typical workloads, significantly reducing this overhead.
Tracing Garbage Collection: The Foundation
Tracing garbage collection takes a fundamentally different approach. Rather than tracking references to objects, it periodically traces through the object graph to identify which objects are reachable from a set of “root” references.
Roots include local variables on thread stacks, global variables, and other references that the runtime can directly access. Any object reachable through a chain of references from these roots is considered “live.” Everything else is garbage.
The most basic tracing algorithm is mark-and-sweep, which operates in two phases:
Mark phase: Starting from roots, the collector traverses all reachable objects, marking each one as “in use.”
Sweep phase: The collector scans through all allocated memory, reclaiming any object not marked as in use.
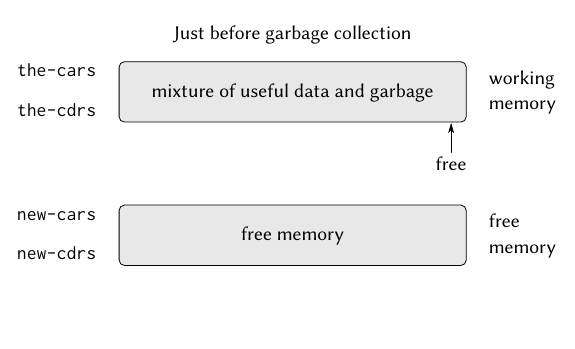
Image source: Wikipedia
This approach immediately solves the cyclic reference problem. Cycles of mutually-referencing objects are either reachable from roots (in which case they’re legitimately live) or unreachable (in which case they’re correctly identified as garbage).
The trade-off is non-determinism. Objects are only reclaimed when a collection occurs, which might be much later than when they become unreachable. More critically, basic mark-and-sweep requires stopping all application threads during collection—a “stop-the-world” pause that can last from milliseconds to seconds depending on heap size and object count.
The Generational Breakthrough
By the 1980s, researchers had observed a consistent pattern across virtually all programs: most objects die young. This observation, formalized as the weak generational hypothesis, became the foundation for a dramatically more efficient approach.
Barry Hayes, in his seminal paper, noted that “newly created objects have a much lower survival rate than older objects.” Empirical studies consistently show that 80% or more of allocated objects become garbage within their first few milliseconds of existence. HTTP request objects, temporary buffers, iterator instances—the vast majority of allocations serve transitory purposes and are discarded almost immediately.
Generational garbage collection exploits this pattern by dividing the heap into regions based on object age. The young generation holds newly allocated objects. The old generation (or tenured generation) holds objects that have survived multiple collection cycles.

Image source: A Bias For Action
The efficiency gains are profound. Because most objects die young, the collector can frequently collect just the young generation—a “minor GC”—reclaiming 80% of garbage by scanning only 20-30% of the heap. Full collections of the entire heap—“major GC”—occur much less frequently.
In Java’s JVM, the young generation is further subdivided into Eden and two survivor spaces (S0 and S1). New objects are allocated in Eden. During a minor GC, surviving objects are copied from Eden and one survivor space to the other survivor space. Objects that survive multiple minor GCs are eventually promoted to the old generation.

Image source: GCEasy Blog
The promotion threshold is configurable via -XX:MaxTenuringThreshold (default 15). Objects that survive 15 minor GCs are moved to the old generation, where they’ll only be collected during major GCs.
The Remembered Set Problem
Generational collection introduces a complexity: how do we find references from the old generation to the young generation? During a minor GC, we need to identify all live objects in the young generation. Roots include thread stacks and globals, but also any references from old-generation objects.
Scanning the entire old generation during every minor GC would defeat the purpose of generational collection. The solution is a remembered set: a data structure tracking potential references from old to young generations.
Most implementations use a card table—a bitmap where each bit (or “card”) represents a region of old-generation memory. When a reference is stored that points from old to young, a write barrier marks the corresponding card as “dirty.” During minor GC, only dirty cards need to be scanned rather than the entire old generation.
Tri-Color Marking: The Foundation of Concurrent Collection
The move toward concurrent collection—where the garbage collector runs alongside the application rather than stopping it—required a more sophisticated marking approach. Dijkstra’s tri-color abstraction, published in 1978, provides the theoretical foundation.
In tri-color marking, every object is conceptually colored:
- White: Not yet visited; potentially garbage
- Gray: Visited but references not yet traced
- Black: Visited and all references traced; definitely live
The algorithm maintains an invariant: no black object ever points directly to a white object. This invariant ensures correctness even as the application mutates the object graph during concurrent marking.
The marking process works like this: roots start as gray. The collector picks a gray object, marks it black, and marks all objects it references as gray (if they were white). This continues until no gray objects remain—at which point, all live objects are black and all white objects are garbage.
For concurrent collection, the critical challenge is maintaining the tri-color invariant when the application might modify references at any time. This is where write barriers become essential.
When the application stores a reference, the write barrier ensures the invariant is preserved. Go’s hybrid write barrier, introduced in Go 1.8, exemplifies this approach: when a reference is written, the write barrier marks both the old referent (if it’s white and the object being modified is black) and the new referent (if it’s white) as gray. This ensures no object transitions from reachable to unreachable without being noticed.
Modern Implementations: Three Philosophies
Different runtime systems have taken different approaches to garbage collection, reflecting their design priorities and the workloads they target.
Java: The Generational Evolution
Java’s garbage collection has evolved dramatically over its history. Early JVMs used a simple generational collector with stop-the-world pauses that could stretch to seconds for large heaps. Modern JVMs offer a portfolio of collectors targeting different use cases:
G1 (Garbage-First) divides the heap into equal-sized regions and prioritizes collecting regions with the most garbage. It achieves predictable pause times by limiting how many regions are collected in each cycle, though pauses still range from tens to hundreds of milliseconds.
ZGC (Z Garbage Collector), production-ready since JDK 15, achieves pause times under 10 milliseconds even for multi-terabyte heaps. It uses colored pointers and load barriers to perform most collection work concurrently, with only brief synchronization pauses.
Shenandoah, developed at Red Hat, similarly targets sub-millisecond pauses through concurrent compaction. It uses Brooks pointers—an extra word in each object pointing to itself that can be updated to point to a new location during compaction.
The key innovation in ZGC and Shenandoah is concurrent compaction. Traditional collectors must pause the application while moving objects because object addresses change during compaction. ZGC uses colored pointers (storing metadata in unused bits of 64-bit pointers) to allow the application to continue executing while objects are being relocated. When the application accesses an object, a load barrier checks the pointer’s color and handles relocation transparently if needed.
Go: Low-Latency Concurrent Collection
Go takes a fundamentally different approach. Rather than generational collection, Go uses a non-generational concurrent tri-color mark-and-sweep collector. This might seem regressive—doesn’t generational collection provide significant efficiency gains?
The decision reflects Go’s design philosophy: simplicity and predictability over raw throughput. A generational collector requires write barriers on every old-to-young reference store, remembered sets that consume memory, and more complex tuning parameters. Go’s collector achieves sub-millisecond pauses with simpler machinery.
Go’s collector operates in three phases:
Mark Setup (Stop-the-World): Enables write barriers. Very brief—typically 10-30 microseconds.
Marking (Concurrent): Uses 25% of available CPU for background marking. Application threads continue executing. Heavy-allocating goroutines may perform “mark assist” work to help complete marking faster.
Mark Termination (Stop-the-World): Disables write barriers and performs finalization. Typically 60-90 microseconds.
The GOGC environment variable controls the collection trigger. A value of 100 (default) means the next collection starts when heap size has grown by 100% since the previous collection. This provides a tunable trade-off between memory usage and CPU overhead.
V8: Parallel and Incremental
V8, the JavaScript engine in Chrome and Node.js, faced unique constraints: JavaScript applications must remain responsive for user interactions. A 100-millisecond pause during a JavaScript-heavy animation would cause visible stuttering.
V8’s Orinoco project transformed a sequential stop-the-world collector into a mostly parallel and concurrent system. The approach combines:
Parallel scavenging: Multiple threads simultaneously collect the young generation, reducing minor GC time by 20-50%.
Concurrent marking: Background threads mark live objects while JavaScript executes, with write barriers tracking mutations.
Incremental compaction: Compaction work is divided into small chunks interleaved with application execution.
V8 maintains a generational layout with young and old generations, but the boundaries between them are less strict than in traditional JVMs. The scavenger (minor GC) copies surviving objects between semi-spaces, while the major GC uses mark-compact for the entire heap.
The results are substantial: concurrent marking and sweeping reduced pause times in heavy WebGL games by up to 50%, and idle-time GC reduced Gmail’s JavaScript heap memory by 45% when idle.
The Performance Trade-off Triangle
Garbage collection inherently involves trade-offs between three dimensions:
Throughput: The percentage of total CPU time spent on application work versus collection. Higher throughput means more work accomplished per unit of wall-clock time.
Latency: The duration of pauses during which the application is unresponsive. Lower latency means smoother user experience and more predictable response times.
Memory: The amount of heap memory required. Lower memory usage means more efficient resource utilization, especially critical in containerized environments.
These dimensions conflict. Achieving low latency often requires more frequent collections (reducing throughput) or maintaining additional data structures (increasing memory). Reducing memory usage typically means more frequent collections or longer pauses.
A 2005 study quantified this trade-off: garbage collection needs approximately five times the memory to match the performance of idealized explicit memory management. This isn’t to say GC is slower—it’s that GC trades memory for developer convenience. With sufficient memory headroom, modern collectors can achieve throughput comparable to manual management while eliminating entire categories of bugs.
Practical Implications for Developers
Understanding garbage collection’s mechanics enables better architectural decisions:
Short-lived objects are cheap. The weak generational hypothesis means that objects that die quickly are essentially free—they’re allocated, used briefly, and reclaimed during the next minor GC without significant overhead. Don’t fear allocations; fear objects that survive.
Object pools are usually counterproductive. Pooling objects to “save GC” often backfires because pooled objects survive into the old generation, where they’re expensive to collect. Modern allocators are highly optimized for short-lived objects; pools add complexity without benefit.
Large objects have hidden costs. Objects that exceed a certain size threshold (configurable, typically around the region size for G1) may be allocated directly in the old generation, bypassing the efficiency of young-generation collection. Very large objects also complicate compaction.
Finalizers are dangerous. Objects with finalizers (in Java) or __del__ methods (in Python) complicate collection. The collector must track these objects separately, potentially delaying their reclamation across multiple collection cycles. More critically, finalizers can resurrect objects—making them reachable again during the collection that’s trying to reclaim them—leading to subtle bugs.
Write barriers have overhead. In languages with concurrent collectors, every reference store incurs write barrier overhead. Code that performs many reference stores may see measurable performance impact. This is particularly relevant for concurrent data structures and high-frequency trading systems.
The Future: Region-Based and Beyond
The frontier of garbage collection research focuses on reducing pause times to near-zero while maintaining throughput. ZGC and Shenandoah have demonstrated that sub-millisecond pauses are achievable even for very large heaps. The next frontier involves region-based collection—dividing the heap into independently collectible regions—and incremental compaction that never requires stopping the world.
Another direction is memory-efficient collection for containerized environments where memory is constrained. Collectors that can operate effectively with smaller heap headroom are increasingly valuable as applications move to cloud deployments with strict memory limits.
The dream of fully concurrent, pauseless garbage collection is nearly realized. For most applications today, GC pauses are measured in microseconds rather than seconds. The sixty-year evolution from McCarthy’s original design has produced systems that manage memory automatically with minimal impact on application performance—a testament to the power of algorithmic innovation and practical engineering.
References
-
McCarthy, J. (1960). Recursive functions of symbolic expressions and their computation by machine, Part I. Communications of the ACM, 3(4), 184-195.
-
Dijkstra, E. W., et al. (1978). On-the-fly garbage collection: An exercise in cooperation. Communications of the ACM, 21(11), 966-975.
-
Hayes, B. (1991). Using key object opportunism to collect old objects. OOPSLA ‘91 Conference Proceedings.
-
Jones, R., Hosking, A., & Moss, J. E. B. (2011). The Garbage Collection Handbook: The Art of Automatic Memory Management. Chapman and Hall/CRC.
-
Hertz, M., & Berger, E. D. (2005). Quantifying the performance of garbage collection vs. explicit memory management. OOPSLA ‘05.
-
Levanoni, O., & Petrank, A. (2006). An on-the-fly reference-counting garbage collector for real-time Java. ACM Transactions on Programming Languages and Systems, 28(1), 31-69.
-
Blackburn, S. M., et al. (2022). Low-latency, high-throughput garbage collection. PLDI 2022.
-
V8 Blog. (2019). Trash talk: the Orinoco garbage collector. Retrieved from https://v8.dev/blog/trash-talk
-
Oracle. (2024). Java Garbage Collection Tuning Guide. Retrieved from https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/
-
Wikipedia. (2025). Garbage collection (computer science). Retrieved from https://en.wikipedia.org/wiki/Garbage_collection_(computer_science)