When Amazon engineers published the Dynamo paper in 2007, they revealed a technique that had been quietly powering some of the world’s largest distributed systems. The core idea—consistent hashing—originated from a 1997 MIT paper by David Karger and colleagues, but it took a decade before the industry fully embraced its elegance. Today, consistent hashing underpins Apache Cassandra, Amazon DynamoDB, Discord’s messaging infrastructure, Netflix’s content delivery network, and virtually every modern distributed database. The algorithm solves a deceptively simple problem: how do you distribute data across servers when those servers keep joining and leaving?
The Hash Function Problem That Breaks Everything
Consider a straightforward approach to distributing 10 million user records across 100 database servers. Hash each user ID to an integer, then use modulo arithmetic:
server = hash(user_id) % 100
This works beautifully until you need to add a 101st server. Suddenly, hash(user_id) % 101 produces completely different results than hash(user_id) % 100. Nearly every user record maps to a different server. You’re not just moving the data that belongs on the new server—you’re reshuffling the entire dataset.
The mathematics are brutal. If $k$ is the number of keys and $n$ is the number of servers, a naive hash function requires moving approximately $\frac{n-1}{n} \cdot k$ keys when adding one server. With 10 million keys, that’s roughly 9.9 million unnecessary data movements. The network becomes saturated, databases lock up, and users experience timeouts.
The Ring Solution: Mapping Servers and Keys to the Same Space
Consistent hashing eliminates this chaos by mapping both servers and data to positions on a conceptual circle—a hash ring. The hash function’s output range, typically $0$ to $2^{32}-1$, wraps around to form a circle. Each server hashes to one or more positions on this ring. Each data key also hashes to a position. To find which server owns a key, you traverse the ring clockwise from the key’s position until you encounter a server.
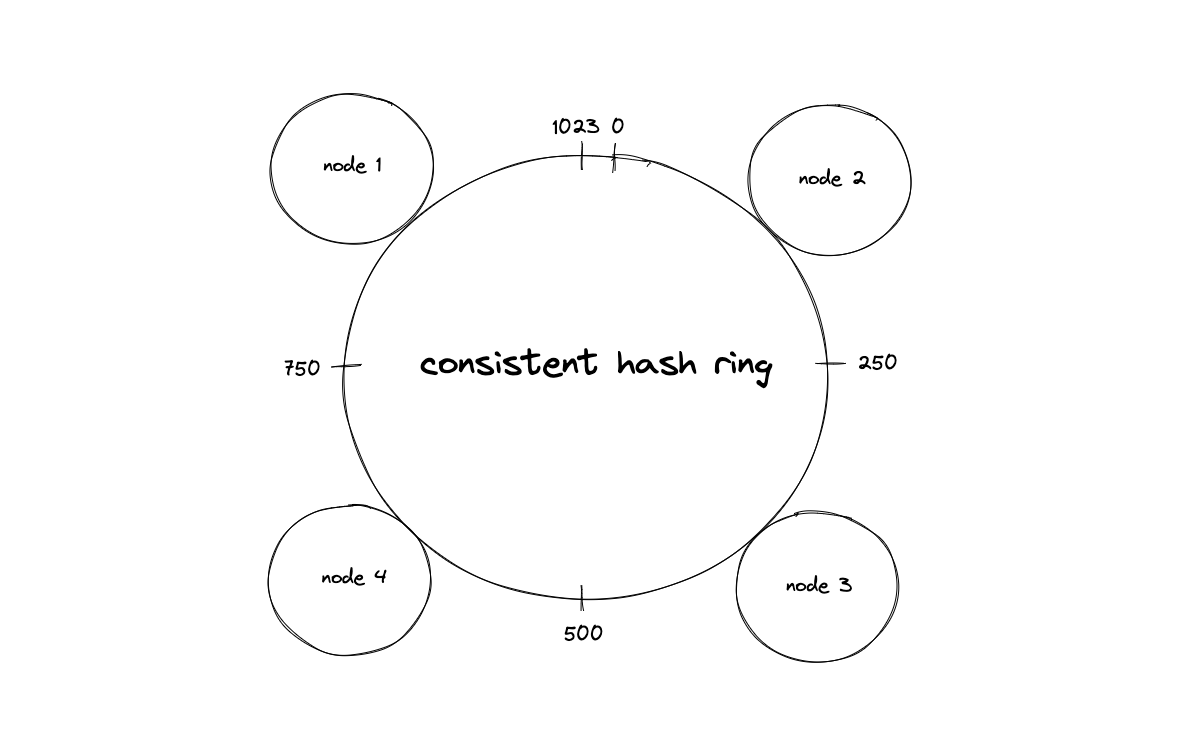
Image source: High Scalability - Consistent Hashing Algorithm
The brilliance becomes apparent when the cluster topology changes. Add a new server at position 75 on the ring, and only keys between the previous server at position 50 and position 75 move to the new server. Keys elsewhere on the ring remain untouched. Remove a server, and its keys migrate to the immediate clockwise neighbor—again, no other server is affected.
The mathematical guarantee is precise: when a server joins or leaves, only $\frac{k}{n}$ keys move on average, where $k$ is the total number of keys and $n$ is the number of servers. This is the theoretical minimum—every key that must move does move, and no key moves unnecessarily.
The Hidden Problem: Uneven Distribution
The basic ring approach has a flaw that becomes apparent at scale. If each server occupies exactly one position on the ring, random placement creates dramatically uneven partitions. One server might own 5% of the ring’s key space while another owns 0.5%. With 10 million keys distributed across 100 servers, that’s a 10x difference in storage load.
This isn’t a theoretical concern. Damian Gryski’s analysis shows that with a single position per server, the load variance follows a power law. Some servers receive $\Theta(\log n / \log \log n)$ times the expected load. For a 1000-node cluster, this means some servers handle 3-4x their fair share while others sit nearly empty.
Virtual Nodes: The Statistical Fix
The solution is beautifully simple: give each server multiple positions on the ring. Instead of hashing “server-A” once, hash “server-A-vn1”, “server-A-vn2”, “server-A-vn3”, and so on. Each physical server becomes many virtual nodes scattered around the ring.
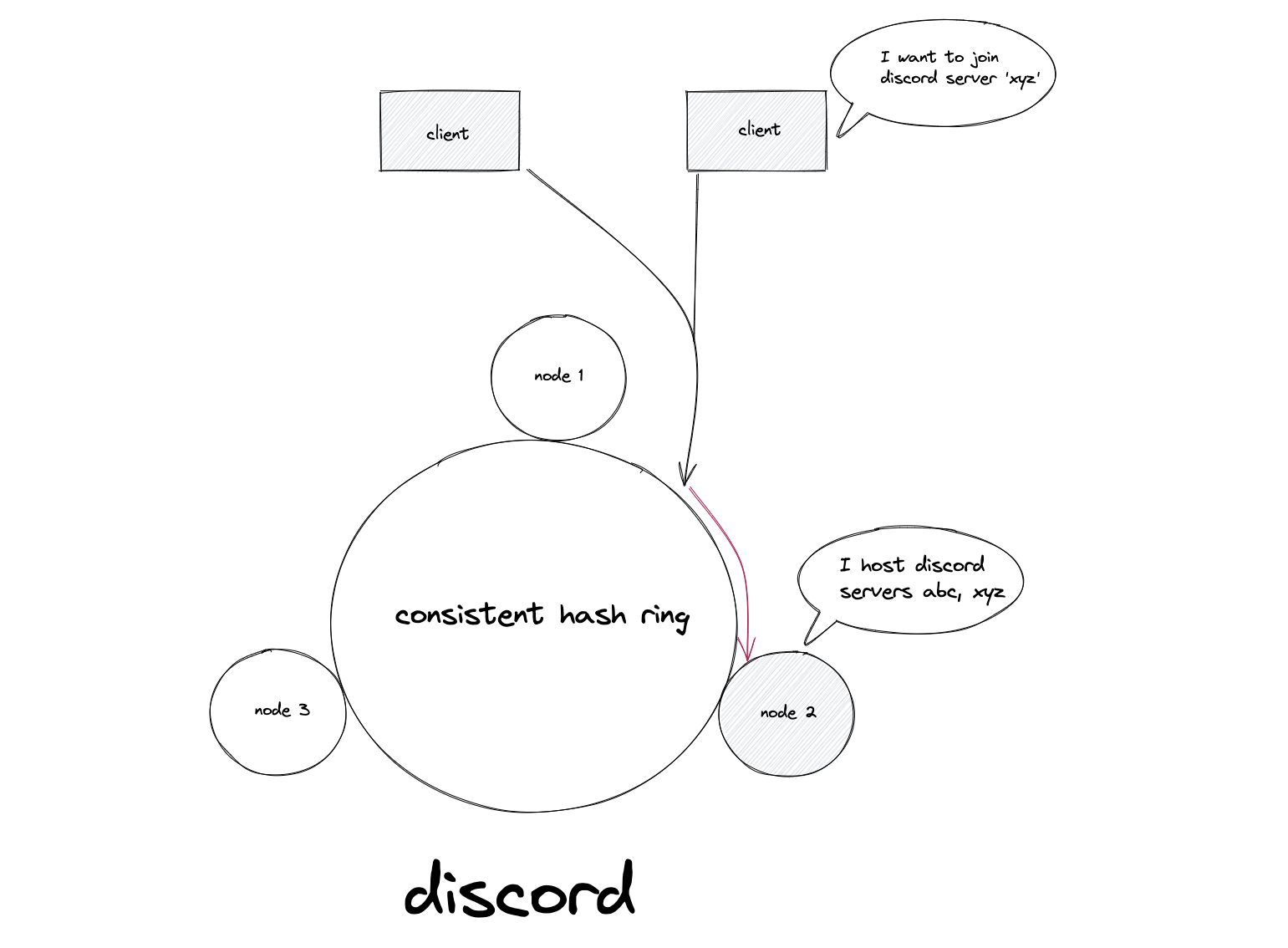
Image source: High Scalability - Consistent Hashing Algorithm
The mathematics of virtual nodes follow from the law of large numbers. With $K$ virtual nodes per server, the standard deviation of load distribution approaches:
$$\sigma = O\left(\sqrt{\frac{\ln n}{K}}\right)$$where $n$ is the number of servers. With 100 virtual nodes per server, the standard deviation drops to approximately 10%. The 99% confidence interval for bucket sizes shrinks to 0.76x to 1.28x of the average load. Increase to 1000 virtual nodes, and the standard deviation falls to 3.2%, with a 99% confidence interval of 0.92x to 1.09x.
The trade-off is memory and lookup time. A ring with 1000 servers and 1000 virtual nodes each requires storing 1 million positions. Each lookup requires a binary search through these positions, which means $O(\log (n \cdot K))$ time complexity—typically around 20 comparisons for large clusters.
Real-World Implementations
Amazon’s Dynamo pioneered consistent hashing in production systems. The 2007 paper described a system where each node is assigned multiple positions on the ring using a variant of consistent hashing. Dynamo uses a replication factor $N$, storing each key on the $N$ consecutive nodes clockwise from its position on the ring. This creates a natural replication strategy—if one node fails, the remaining replicas can serve requests.
Apache Cassandra takes a similar approach but uses a token ring with explicit token assignment. Each node is responsible for the range of tokens between its position and its predecessor’s position. Cassandra’s default configuration uses 256 virtual nodes per physical server, providing excellent load distribution. The Murmur3Partitioner hashes partition keys using MurmurHash3, a fast non-cryptographic hash function that produces uniformly distributed 64-bit tokens.
Redis Cluster takes a different approach. Instead of consistent hashing, it uses 16,384 fixed hash slots computed as CRC16(key) mod 16384. Each node claims ownership of a subset of slots. When adding or removing nodes, slots migrate between nodes. This approach provides similar minimal-rebalancing guarantees while being simpler to reason about and debug.
Bounded Loads: Preventing Hot Spots
Even with virtual nodes, consistent hashing can produce hot spots. A viral video or a popular user profile generates disproportionate traffic to one key. The server hosting that key becomes overwhelmed while others sit idle.
Google’s 2016 paper “Consistent Hashing with Bounded Loads” addresses this problem. The algorithm sets an upper bound on any server’s load relative to the average. If a server exceeds its quota, the request “falls through” to the next server on the ring. The mathematical guarantee is that with a balancing parameter $c = 1 + \epsilon$, no server receives more than $\lceil c \cdot \frac{m}{n} \rceil$ requests, where $m$ is the total number of requests.
Vimeo implemented bounded-load consistent hashing in their HAProxy configuration. Their engineering blog documents a 4x reduction in load variance during traffic spikes. The algorithm adds minimal overhead—a few extra hash computations per request—while dramatically improving cluster stability.
Algorithmic Variants and Trade-offs
The research community has produced several consistent hashing variants, each optimizing different aspects:
Jump Hash (Google, 2014) eliminates the ring entirely. It’s a pure mathematical function that maps keys directly to bucket indices with $O(\ln n)$ time complexity and zero memory overhead. The distribution is nearly perfect—standard deviation of 0.000000764%. The catch: it only supports adding or removing nodes at the end of the range, making it unsuitable for clusters where arbitrary nodes can fail.
Rendezvous Hashing (also known as Highest Random Weight hashing) takes a different approach. For each key, compute a hash combining the key with each server name, then pick the server with the highest hash value. This produces excellent distribution but requires $O(n)$ hash computations per lookup—one for each server. For small clusters, this is acceptable. For clusters with thousands of nodes, the overhead becomes prohibitive.
Multi-Probe Consistent Hashing (Google, 2015) hashes each server once but hashes each key multiple times during lookup. With 21 hash probes, the peak-to-mean load ratio drops to 1.05. Memory usage is $O(n)$ instead of $O(n \cdot K)$, making it suitable for very large clusters.
Implementation Considerations
When implementing consistent hashing, the choice of hash function matters more than you might expect. Cryptographic hashes like MD5 or SHA-1 produce excellent distributions but are computationally expensive. For a system handling millions of requests per second, the hash function becomes a bottleneck.
MurmurHash3, xxHash, and SipHash offer better performance while maintaining statistical properties. xxHash in particular can process data at several gigabytes per second on modern CPUs—fast enough that hash computation rarely becomes the limiting factor.
The data structure for storing ring positions deserves attention. A sorted array with binary search is simple and cache-friendly. For dynamic clusters where nodes frequently join and leave, a balanced binary search tree or a skip list provides $O(\log n)$ insertion and deletion. The gossip protocol used by Cassandra and Dynamo allows nodes to exchange ring state without central coordination, but eventual consistency means different nodes might temporarily disagree about ring membership.
When Consistent Hashing Isn’t the Answer
Not every distributed system needs consistent hashing. If your cluster size is fixed and predictable, simple hash partitioning works fine. If you’re building a caching layer and can tolerate occasional cache misses during rehashing, the added complexity isn’t worth it.
Systems that require strong consistency guarantees often prefer other approaches. Google’s Spanner uses sharding with Paxos-based replication. CockroachDB uses range-based partitioning with Raft consensus. These systems make different trade-offs: they accept more coordination overhead in exchange for stronger consistency and more predictable performance.
The Enduring Elegance
Twenty-eight years after Karger’s original paper, consistent hashing remains one of distributed systems’ most elegant solutions. Its beauty lies in matching the mathematical minimum for data movement while remaining simple enough to implement in an afternoon. The core insight—map both servers and data to the same space, then use spatial proximity to determine ownership—transcends any particular implementation.
Modern systems layer sophistication on top of this foundation: virtual nodes for better distribution, bounded loads for handling hot spots, and gossip protocols for decentralized coordination. But the ring remains. When you store a file in Dropbox, stream a video on Netflix, or send a message on Discord, consistent hashing is quietly determining which server handles your request. The algorithm works because it doesn’t try to be clever. It accepts randomness as an ally, using probability to achieve what deterministic approaches cannot: scalable, fault-tolerant data distribution with mathematically provable guarantees.
References
-
Karger, D., Lehman, E., Leighton, T., Panigrahy, R., Levine, M., & Lewin, D. (1997). Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. Proceedings of the 29th Annual ACM Symposium on Theory of Computing.
-
DeCandia, G., et al. (2007). Dynamo: Amazon’s Highly Available Key-value Store. Proceedings of the 21st ACM Symposium on Operating Systems Principles.
-
Mirrokni, V., Thorup, M., & Zadimoghaddam, M. (2016). Consistent Hashing with Bounded Loads. arXiv preprint arXiv:1608.01350.
-
Lamping, J., Veach, E., & Tremback, C. (2014). A Fast, Minimal Memory, Consistent Hash Algorithm. Google Research.
-
Appleton, B., & O’Reilly, M. (2015). Multi-Probe Consistent Hashing. Google Research.
-
Gryski, D. (2018). Consistent Hashing: Algorithmic Tradeoffs. Medium.
-
DataStax. Apache Cassandra 3.0 Documentation: Consistent Hashing.
-
Vimeo Engineering Blog. (2016). Improving Load Balancing with a New Consistent-Hashing Algorithm.