In March 2024, a team of researchers attempted to deploy a 70-billion parameter language model on a single NVIDIA H100 GPU with 80GB of VRAM. The model weights alone consumed approximately 140GB in FP16—already exceeding their hardware capacity. But even after applying 4-bit quantization to squeeze the weights down to ~40GB, the system still ran out of memory when processing contexts beyond 8,000 tokens. The culprit wasn’t the model size. It was something far more insidious: the KV cache.
This scenario plays out across organizations daily. The assumption that “bigger VRAM equals longer contexts” fails because GPU memory consumption in LLM inference doesn’t scale the way most engineers expect. Understanding why requires diving into the architecture of transformer attention and the hidden memory dynamics that govern modern language model serving.
The Anatomy of LLM Memory Consumption
When an LLM processes text, three primary components compete for GPU memory:
Model weights are the learned parameters—the billions of floating-point numbers that encode the model’s knowledge. A 70B parameter model requires roughly 140GB in FP16 precision, 70GB in FP8, or about 40GB with aggressive 4-bit quantization.
Activation memory holds intermediate results during computation. These temporary buffers store attention scores, feed-forward outputs, and other intermediate states. For most inference scenarios, this represents a relatively small and predictable overhead.
The KV cache is where things get interesting—and expensive.
During autoregressive generation, each token produced requires computing attention against all previous tokens in the sequence. Without caching, generating token 1,000 would require re-computing attention for all 999 previous tokens—quadratic complexity that quickly becomes intractable. The KV cache solves this by storing the key and value projections from every previous position, transforming $O(n^2)$ computation into $O(n)$ space.
The tradeoff is memory. Substantial memory.
The Mathematics of KV Cache Growth
The KV cache memory formula reveals why this hidden cost can exceed model weights:
$$\text{KV Cache} = 2 \times n_{\text{layers}} \times \text{batch\_size} \times \text{seq\_len} \times n_{\text{kv\_heads}} \times d_{\text{head}} \times \text{bytes\_per\_element}$$The factor of 2 accounts for storing both keys and values. For standard Multi-Head Attention (MHA), the formula simplifies further:
$$\text{KV Cache} = 2 \times n_{\text{layers}} \times \text{batch\_size} \times \text{seq\_len} \times d_{\text{model}} \times \text{bytes}$$Consider LLaMA 2 70B with its 80 layers and hidden dimension of 8,192. At 4,096 tokens with FP16 precision:
$$\text{KV Cache} = 2 \times 80 \times 1 \times 4096 \times 8192 \times 2 = 10.7 \text{ GB}$$But this assumes standard multi-head attention. LLaMA 2 actually uses Grouped Query Attention (GQA) with only 8 KV heads instead of 64, reducing this by 8× to approximately 1.3GB. Without GQA, the same model would require 10.7GB just for the KV cache at a modest 4K context.
Scale this to 128K context—the “long context” that modern models promise—and the numbers become staggering:
| Model | Context Length | KV Cache (MHA) | KV Cache (GQA) |
|---|---|---|---|
| LLaMA 7B | 4K | 2.1 GB | 2.1 GB* |
| LLaMA 7B | 32K | 17 GB | 17 GB* |
| LLaMA 7B | 128K | 68 GB | 68 GB* |
| LLaMA 2 70B | 4K | 10.7 GB | 1.3 GB |
| LLaMA 2 70B | 32K | 85.6 GB | 10.7 GB |
| LLaMA 2 70B | 128K | 342 GB | 42.8 GB |
*LLaMA 7B uses standard MHA without GQA optimization.
The crossover point—where KV cache exceeds model weights—occurs at approximately 32K tokens for most models. Beyond this threshold, every additional token costs more in cache memory than the model itself.
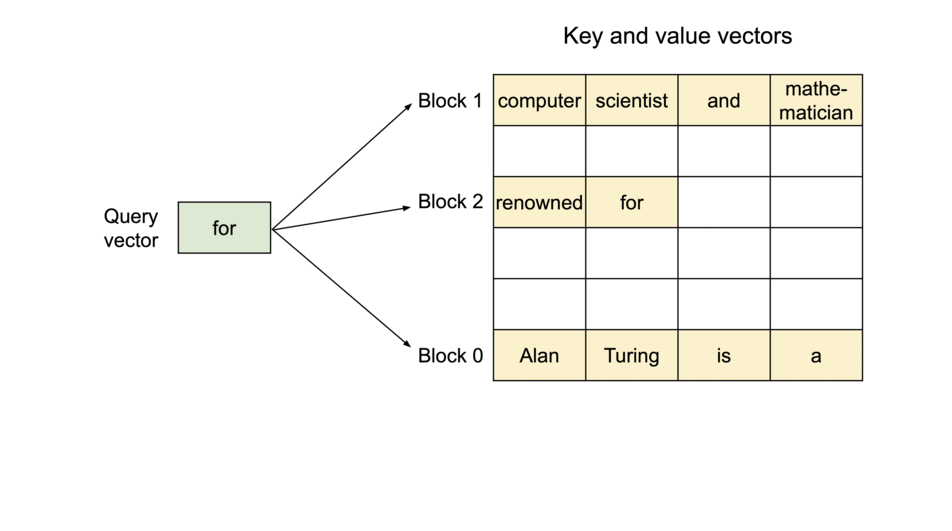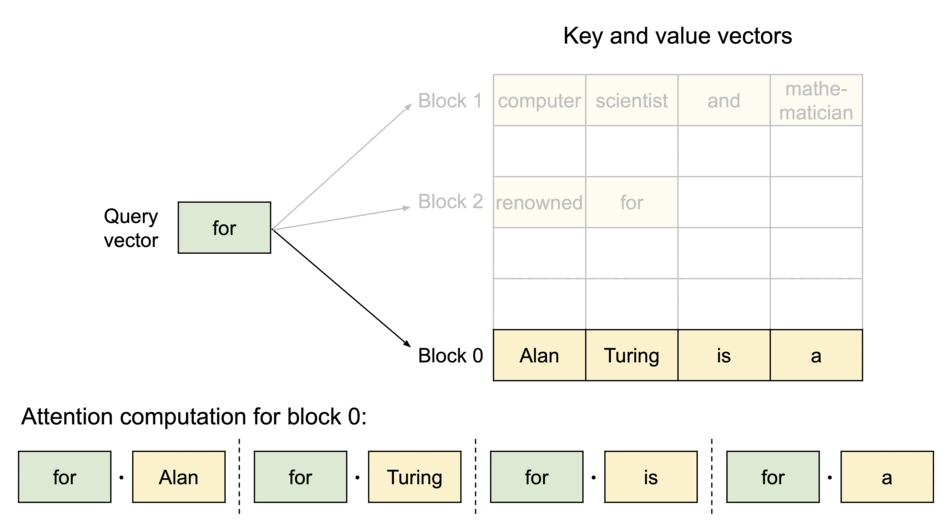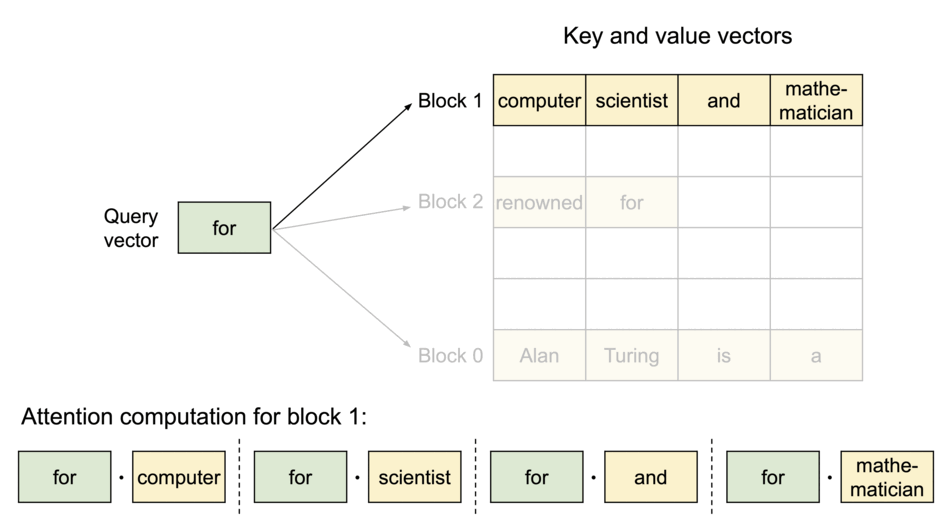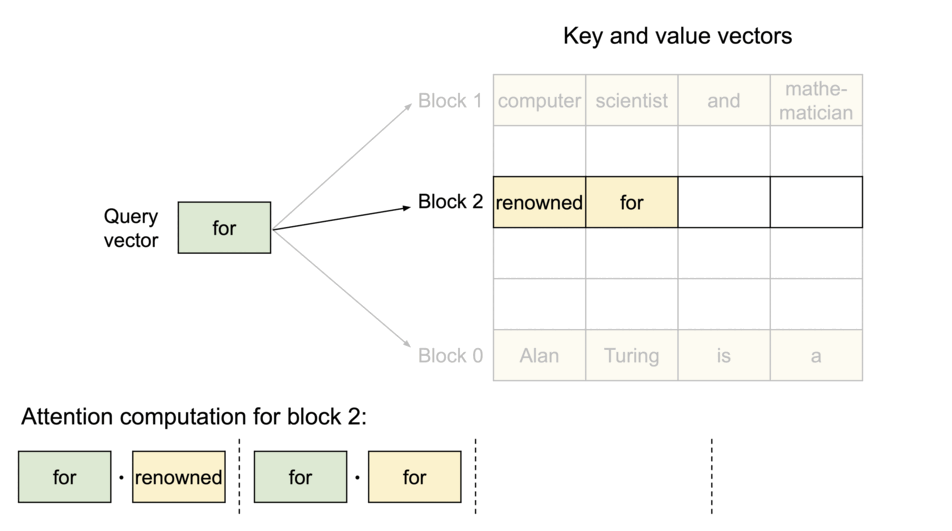
Image source: vLLM Blog — PagedAttention partitions the KV cache into blocks that don’t require contiguous memory.
The Memory Bandwidth Bottleneck
Memory capacity is only half the problem. The real performance killer is memory bandwidth.
Modern GPUs like the NVIDIA A100 deliver 312 TFLOPS of FP16 compute but only 2 TB/s of memory bandwidth. This creates a compute-to-bandwidth ratio of roughly 156 operations per byte transferred. When a workload’s arithmetic intensity falls below this threshold, the GPU becomes memory-bound—spending more time waiting for data than performing calculations.
During the decode phase of LLM inference, each generated token requires reading the entire KV cache from High Bandwidth Memory (HBM) into on-chip SRAM. The GPU memory hierarchy makes this expensive:
- SRAM (on-chip): ~20MB total, ~19 TB/s bandwidth
- HBM (GPU VRAM): 40-80GB, 1.5-3.4 TB/s bandwidth
- L2 Cache: 40MB (A100), shared across SMs
For a 70B model with 32K context, each token generation involves transferring over 10GB of KV cache data. At 2 TB/s, that’s 5ms just for memory transfer—before any computation begins. With typical generation speeds of 20-50 tokens per second, the GPU spends most of its time idle, waiting for data.

Image source: ObjectiveMind.AI — GPU architecture showing the critical gap between SRAM speed and HBM capacity.
This explains why simply adding more VRAM doesn’t solve the throughput problem. Even with infinite memory, bandwidth limits how fast that memory can be accessed.
PagedAttention: Virtual Memory for LLMs
The vLLM project, introduced in September 2023, addressed a different aspect of the memory problem: fragmentation and over-provisioning.
Traditional LLM serving systems allocate contiguous memory blocks for each request’s KV cache, often over-reserving for maximum possible sequence length. The vLLM paper measured that existing systems waste 60-80% of memory due to fragmentation and over-reservation.
PagedAttention borrows from operating system virtual memory concepts:
Block partitioning: The KV cache is divided into fixed-size blocks, each containing keys and values for a fixed number of tokens (typically 16).
Non-contiguous allocation: Blocks don’t need to be contiguous in physical memory. A “block table” maps logical blocks to physical blocks, similar to page tables in OS memory management.
On-demand allocation: Memory is allocated only as tokens are generated, eliminating over-provisioning.
Reference counting and Copy-on-Write: Multiple sequences can share blocks (for parallel sampling or beam search), with copy-on-write semantics ensuring correctness.
The result is near-optimal memory utilization with under 4% waste, compared to 60-80% in previous systems. This allows higher batch sizes and significantly improved throughput.

Image source: vLLM Blog — Generation process showing how logical blocks map to non-contiguous physical blocks.
In benchmarks, vLLM achieved up to 24× higher throughput than HuggingFace Transformers and 3.5× higher than TGI (Text Generation Inference) on the same hardware.
Grouped Query Attention: Architectural Efficiency
While PagedAttention optimizes memory management, Grouped Query Attention (GQA) reduces the memory required in the first place.
In standard Multi-Head Attention, each of the $h$ query heads has its own corresponding key and value head. GQA groups multiple query heads to share a single KV head. If a model has 64 query heads but only 8 KV heads, each KV head is shared by 8 query heads.
The memory reduction is proportional to the grouping factor:
$$\text{Memory Reduction} = \frac{n_{\text{query\_heads}}}{n_{\text{kv\_heads}}}$$LLaMA 2 70B uses GQA with 64 query heads and 8 KV heads—an 8× reduction in KV cache size. This architectural choice is what makes 70B models practical for longer contexts on consumer hardware.
The tradeoff is quality. Sharing KV heads introduces approximation, though research shows that moderate grouping (up to 8×) causes negligible quality degradation for most tasks. LLaMA 3 extends this further, using 8 KV heads across all model sizes.
FlashAttention: IO-Aware Computation
FlashAttention, introduced by researchers at Stanford in May 2022, takes a different approach to the memory bottleneck. Rather than optimizing allocation, it optimizes the computation itself.
The key insight: standard attention materializes an $N \times N$ attention matrix in HBM, requiring $O(N^2)$ memory writes and reads. For long sequences, this dominates execution time.
FlashAttention uses tiling to compute attention in blocks that fit in on-chip SRAM:
- Load blocks of Q, K, and V from HBM to SRAM
- Compute attention for the block entirely in SRAM
- Write only the final output back to HBM
This reduces HBM accesses from $O(N^2)$ to $O(N)$ while computing exact attention (no approximation). The original paper demonstrated 3× speedup on GPT-2 and enabled the first transformer models to process 64K token sequences effectively.
FlashAttention-2 (2023) further optimized the algorithm, achieving 2× speedup over the original by better parallelism and work partitioning. Modern LLM serving frameworks now consider FlashAttention essential for any production deployment.
The Economics of Memory Optimization
These optimizations don’t just improve performance—they fundamentally change deployment economics.
Consider serving a 70B model with 32K context at scale:
| Configuration | Memory Required | Hardware | Approximate Cost |
|---|---|---|---|
| No optimization (MHA) | ~85GB KV + 40GB weights | 2× A100 80GB | ~$30,000+ |
| GQA only | ~11GB KV + 40GB weights | 1× A100 80GB | ~$15,000 |
| GQA + PagedAttention | ~11GB KV + 40GB weights, efficient batching | 1× A100 80GB | ~$15,000 |
| GQA + PagedAttention + INT8 KV | ~5.5GB KV + 20GB weights (INT8) | 1× A100 40GB | ~$7,000 |
The LMSYS Chatbot Arena provides a real-world case study. After integrating vLLM, they reduced their GPU count by 50% while handling 30,000 daily requests with peaks of 60,000—all on university-sponsored hardware.
Practical Considerations for Deployment
When planning LLM deployment, memory planning requires accounting for all consumers:
# Simplified memory estimation
model_memory = params * bytes_per_param # 70B * 2 = 140GB for FP16
kv_cache_memory = 2 * layers * batch * seq_len * kv_heads * head_dim * bytes
activation_memory = batch * seq_len * hidden_dim * layers * 0.1 # Rough estimate
overhead = 0.1 * (model_memory + kv_cache_memory + activation_memory)
total_memory = model_memory + kv_cache_memory + activation_memory + overhead
The batch size and sequence length are the levers you control. Doubling either doubles KV cache memory. The optimal configuration maximizes batch size within memory constraints—the point where throughput plateaus before latency degrades unacceptably.
For long-context applications, consider:
-
Context window sizing: Do you actually need 128K context? Many applications only require 8K-16K, reducing cache by 8-16×.
-
Quantization: INT8 KV cache quantization halves memory with typically minimal quality impact. INT4 provides 4× reduction but may require calibration.
-
Prefix caching: Many requests share system prompts or few-shot examples. vLLM’s automatic prefix caching eliminates redundant computation and storage.
-
Sliding window attention: For applications where only recent context matters, limiting attention to a sliding window bounds cache size.
Looking Forward
The memory bottleneck in LLM inference isn’t going away—it’s becoming more critical as models grow and context windows expand. The next generation of hardware (HBM4, 3D-stacked memory) will help, but software optimization will remain essential.
Emerging techniques include:
KV cache compression: Beyond quantization, methods like H2O (Heavy-Hitter Oracle) and streaming LLM selectively evict unimportant KV entries, enabling infinite-length generation with bounded memory.
Multi-query attention (MQA): An extreme version of GQA where all query heads share a single KV head. Used in models like PaLM for maximum inference efficiency.
Speculative decoding: Uses a smaller “draft” model to generate candidate tokens that the larger model verifies, amortizing memory access costs across multiple tokens.
The fundamental insight remains: LLM inference is memory-bound, not compute-bound. Understanding this distinction—and the architectural innovations that address it—is essential for building efficient, cost-effective AI systems.
References
-
Kwon, W., et al. (2023). “Efficient Memory Management for Large Language Model Serving with PagedAttention.” ACM SOSP 2023. arXiv:2309.06180
-
Dao, T., et al. (2022). “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness.” NeurIPS 2022. arXiv:2205.14135
-
Ainslie, J., et al. (2023). “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints.” arXiv:2305.13245
-
NVIDIA. “Mastering LLM Techniques: Inference Optimization.” NVIDIA Developer Blog.
-
Pope, R., et al. (2022). “Efficiently Scaling Transformer Inference.” MLSys 2023.
-
Shazeer, N. (2019). “Fast Transformer Decoding: One Write-Head is All You Need.” arXiv:1911.02150