On July 20, 2016, Stack Overflow went offline for 34 minutes. The culprit wasn’t a database failure, a network outage, or a cyberattack. It was a regular expression—a tool developers use every day without a second thought. The pattern ^[\s\u200c]+|[\s\u200c]+$ was used to trim whitespace from user-submitted content. When a post containing approximately 20,000 consecutive whitespace characters appeared on the homepage, the regex engine entered a computational spiral that consumed 100% CPU across multiple web servers.
This wasn’t a bug in the regex implementation. The engine was working exactly as designed. The problem lay in a fundamental mismatch between how most modern regex engines work and what programmers expect them to do.
The Two Paths of Regex Matching
Regular expressions have theoretical roots in automata theory, specifically finite automata. A finite automaton is a simple machine that reads input one character at a time and transitions between states based on what it reads. There are two types: Deterministic Finite Automata (DFA) and Non-deterministic Finite Automata (NFA).
In a DFA, each state has exactly one transition for each possible input character. The machine never faces a choice—it simply follows the path dictated by the input. This makes DFAs fast and predictable: they process any string in linear time, proportional to the string’s length.

Image source: swtch.com - Regular Expression Matching Can Be Simple And Fast
NFAs, by contrast, can have multiple valid transitions for the same input character. When faced with ambiguity, the machine must explore different paths. There are two ways to implement this exploration: the “correct” way and the “fast to implement” way.
Ken Thompson, who introduced regular expressions to programmers in the 1960s, designed an elegant solution. His NFA simulation tracks all possible states simultaneously, advancing them in parallel as it reads the input. This approach—often called the Thompson NFA—maintains linear time complexity.
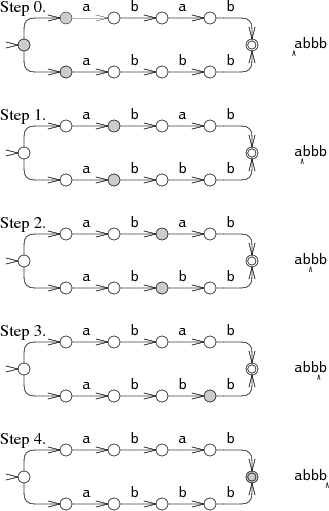
Image source: swtch.com - Regular Expression Matching Can Be Simple And Fast
But most modern regex engines—those in Perl, Python, Java, Ruby, PHP, and JavaScript—take a different approach. They use backtracking.
The Backtracking Trap
A backtracking NFA explores one path at a time. When it reaches a decision point, it chooses one branch and continues. If that branch fails, it backtracks to the decision point and tries another. This recursive approach is intuitive and easy to implement, but it has a fatal flaw: the engine might revisit the same character positions exponentially many times.
Consider the innocuous-looking pattern (a+)+. This matches one or more ‘a’ characters, repeated one or more times. Both quantifiers (+) are greedy, meaning they try to match as much as possible. When the engine tries to match this pattern against the string aaaaaaaaaaaaX (without a matching ‘X’), here’s what happens:
The inner a+ matches all the ‘a’ characters. The outer group has satisfied its + requirement with one iteration. But there’s no ‘X’ at the end. So the engine backtracks. The inner a+ gives up one ‘a’, leaving it for a potential second iteration of the outer group. That second iteration tries, but still no ‘X’. Backtrack further. The inner a+ in the first iteration gives up another ‘a’, allowing the inner a+ in the second iteration to grow. And so on.
For a string of $n$ characters, the number of possible ways to partition the string between iterations grows combinatorially. The pattern (a+)+ creates approximately $2^n$ different paths to explore. Each additional character doubles the search space.
Russ Cox demonstrated this dramatically in his landmark 2007 article. The pattern a?^n a^n (that’s n copies of a? followed by n copies of a) matched against a^n takes Perl over 60 seconds for a 29-character string. A Thompson NFA implementation handles it in 20 microseconds—a million times faster.

Image source: swtch.com - Regular Expression Matching Can Be Simple And Fast
The graphs tell a stark story. On the left, Perl’s execution time curves exponentially upward. On the right, the Thompson NFA line is nearly flat. For a 100-character string, the Thompson NFA finishes in under 200 microseconds. Perl would require over $10^{15}$ years.
Why Everyone Uses the Slow Version
If Thompson’s algorithm is so much better, why do most languages use backtracking? The answer lies in features.
Backtracking engines support extensions that go beyond formal regular expressions. Backreferences (matching a previously captured group) are the most notable example. The pattern (a|b)\1 matches “aa” or “bb” but not “ab”—something no pure automaton can do efficiently. These extensions make regex more powerful and expressive, but they require the backtracking approach.
This creates a tradeoff: you get powerful features, but you lose the linear time guarantee. For most patterns and most inputs, backtracking works fine. But certain “pathological” patterns can trigger catastrophic behavior.
The Anatomy of Catastrophic Backtracking
Catastrophic backtracking occurs when nested quantifiers create overlapping possibilities. The pattern (x+x+)+y is a textbook example. When matching against xxxxxxxxxxxx (without the ‘y’), the engine must try all possible ways to partition the ‘x’ characters between the two inner x+ groups across all possible iterations of the outer group.
The number of steps grows as $O(2^n)$ where $n$ is the string length. At 10 ‘x’ characters, the engine needs 2,557 steps to determine there’s no match. At 11 characters, it needs 5,117 steps. At 12 characters, 10,237 steps. Each additional character roughly doubles the work.

Image source: abstractsyntaxseed.com - NFA vs DFA
This isn’t just an academic concern. The Stack Overflow incident demonstrates real-world impact. The regex ^[\s\u200c]+|[\s\u200c]+$ looks harmless—it trims whitespace and a specific Unicode character from both ends of a string. But with 20,000 whitespace characters, the backtracking engine tried so many paths that the servers became unresponsive.
Solutions: Atomic Groups and Possessive Quantifiers
Most regex engines provide mechanisms to prevent catastrophic backtracking. Atomic groups (?>...) treat their contents as a single unit—once the group matches, the engine cannot backtrack into it. Possessive quantifiers like a++ work similarly: they match greedily and refuse to give back characters.
Consider the problematic pattern (x+x+)+y. Using possessive quantifiers: (x++x++)+y. Now when the engine matches all the ‘x’ characters, it cannot give them back. When ‘y’ fails, the entire match fails immediately—in just 7 steps instead of millions.
Another solution is to rewrite patterns to eliminate ambiguity. Instead of ^(.*?,){11}P to find the 12th comma-separated field starting with ‘P’, use ^([^,\r\n]*,){11}P. The character class [^,\r\n] explicitly excludes commas, so there’s only one way to match each field.
The RE2 Approach: Guaranteed Linear Time
Some regex engines refuse to compromise on performance. RE2, developed by Russ Cox at Google, implements a Thompson-style NFA with guaranteed linear time complexity. It deliberately omits features like backreferences that would require backtracking.
RE2 is used in production at Google for Code Search and other systems where users can submit arbitrary regex patterns. The guarantee of predictable performance matters more than supporting every regex feature.
The tradeoff is clear: RE2 cannot match patterns that require backreferences. But for the vast majority of regex use cases—validation, searching, extraction—RE2’s capabilities are sufficient, and the performance guarantee is invaluable.
Recognizing Dangerous Patterns
Not every regex with nested quantifiers is dangerous. The key is whether different paths can match the same text. The pattern (a+b+|c+d+)+y is safe because each alternative starts with a different character. There’s no ambiguity about which branch to take.
But when quantifiers nest and the matched content overlaps, beware. Patterns like (a*)*, (a|a)*, and (a?){n} can all exhibit exponential behavior on certain inputs.
A practical rule: if you can’t determine locally which branch of an alternative will succeed, or when a loop can accept input in multiple ways, you may have a problem. Testing with long strings that don’t match is the surest way to detect catastrophic backtracking.
The Bigger Picture
The regex performance problem is part of a broader class of vulnerabilities called Algorithmic Complexity Attacks, or Regular Expression Denial of Service (ReDoS). An attacker who can control either the regex pattern or the input string can exploit these weaknesses to exhaust CPU resources.
This has security implications beyond performance. Web applications that accept user-provided regex patterns or process user input through complex regexes are particularly vulnerable. The fix isn’t always obvious—rewriting regexes requires understanding both the intended behavior and the performance characteristics.
The Stack Overflow incident led to immediate changes. The offending regex was replaced with a simpler pattern, and timeouts were added to prevent any single regex from monopolizing the CPU. But the underlying issue—the fundamental tension between regex features and performance guarantees—remains.
References
- Cox, R. (2007). “Regular Expression Matching Can Be Simple And Fast.” swtch.com
- Thompson, K. (1968). “Regular Expression Search Algorithm.” Communications of the ACM.
- Weideman, N., et al. (2014). “Analyzing Catastrophic Backtracking Behavior in Practical Regular Expression Matching.” arXiv:1405.5599
- Stack Exchange. (2016). “Outage Postmortem - July 20, 2016.” stackstatus.net
- Goyvaerts, J. “Runaway Regular Expressions: Catastrophic Backtracking.” regular-expressions.info