On September 20, 2015, Amazon DynamoDB in US-East-1 went dark for over four hours. The root cause wasn’t a hardware failure or a cyberattack—it was a feedback loop. Storage servers couldn’t retrieve their partition assignments from a metadata service, so they retried. The metadata service became overwhelmed. More timeouts. More retries. More overload. Engineers eventually had to firewall the metadata service from storage servers entirely, effectively taking DynamoDB offline to break the cycle.
This was a textbook cascade failure: a small perturbation that spiraled into total system collapse. And it’s precisely the kind of disaster that circuit breakers are designed to prevent.
The Hidden Feedback Loops in Distributed Systems
Cascading failures share a common anatomy: a reinforcing feedback cycle where an initial problem creates conditions that make the problem worse. In distributed systems, this typically looks like:
- A service experiences elevated latency or errors
- Clients retry failed requests
- Retries increase load on the struggling service
- Higher load causes more failures
- More failures trigger more retries
In System Dynamics terminology, these are called “reinforcing cycles”—the most dangerous patterns because they don’t self-correct. They accelerate. The DynamoDB incident followed this exact pattern: a transient network problem caused some storage servers to miss their partition assignments, triggering retries that overwhelmed the metadata service.
What makes cascade failures particularly insidious is that they often strike without warning. A system operating comfortably within its limits can suddenly tip into dysfunction when a single variable crosses a threshold. The preconditions—failover mechanisms, retry logic, shared resource pools—are features we deliberately build into distributed systems for reliability. They become liabilities only when conditions push them past critical boundaries.
The Circuit Breaker: Breaking the Cycle
The circuit breaker pattern, popularized by Michael Nygard in his book Release It!, provides a mechanism to interrupt these feedback loops. The name comes from electrical engineering: when current exceeds safe levels, a circuit breaker trips to prevent damage. The software equivalent monitors for failures and “trips” to prevent cascading damage.
At its core, a circuit breaker is a state machine with three primary states:

Image source: Resilience4j Documentation
Closed State: Normal operation. Requests flow through to the downstream service. The circuit breaker maintains a sliding window of outcomes, tracking successes and failures. When the failure rate or slow call rate exceeds a configured threshold, the breaker transitions to Open.
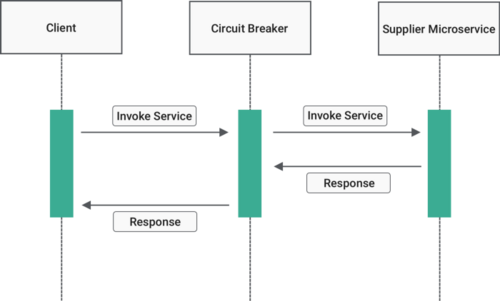
Image source: Wikipedia - Circuit Breaker Design Pattern
Open State: The breaker “trips.” All subsequent requests fail immediately—no actual calls are made to the struggling service. This gives the downstream service time to recover. After a configured wait duration, the breaker transitions to Half-Open.

Image source: Wikipedia - Circuit Breaker Design Pattern
Half-Open State: A probationary period. The breaker allows a limited number of test requests through. If these succeed, the breaker assumes the downstream service has recovered and transitions back to Closed. If they fail, the breaker returns to Open and the wait timer restarts.

Image source: Wikipedia - Circuit Breaker Design Pattern
The elegance of this design is in how the half-open state prevents thundering herd problems. When a service recovers, it might only support limited throughput initially. The half-open state allows only a few probe requests, protecting a recovering service from being immediately overwhelmed by pent-up demand.
The Mathematics of State Transitions
Understanding when a circuit breaker transitions requires understanding its metrics. Modern implementations like Resilience4j use sliding windows to track outcomes.
Count-Based Sliding Window
A count-based window tracks the last N calls. If the window size is 100, the breaker maintains outcomes for the most recent 100 calls. When call 101 arrives, the oldest outcome is evicted.
The failure rate is calculated as:
$$\text{Failure Rate} = \frac{\text{Number of Failed Calls}}{\text{Total Calls in Window}} \times 100$$The breaker transitions to Open when:
- The failure rate exceeds
failureRateThreshold(default: 50%) - The slow call rate exceeds
slowCallRateThreshold(default: 100%) - At least
minimumNumberOfCallshave been recorded (default: 100)
The minimum number of calls requirement prevents premature tripping. If the breaker opens after just two failed calls, random transient errors could cause unnecessary service disruption. With minimumNumberOfCalls = 10, even if all 10 calls fail, the breaker won’t trip until 10 calls have accumulated—giving statistical significance to the failure pattern.
Time-Based Sliding Window
A time-based window aggregates outcomes over the last N seconds. Instead of tracking individual calls, the implementation uses partial aggregations (buckets) for each second.
This approach has advantages for services with variable traffic patterns. During low-traffic periods, a count-based window might take hours to fill, delaying failure detection. A time-based window always reflects the last N seconds, regardless of call volume.
The memory footprint differs significantly. A count-based window stores N individual measurements—O(N) space. A time-based window stores N partial aggregations (each containing just a few integers for failure counts, slow call counts, and total counts)—nearly O(1) relative to call volume.
Thread Isolation: Beyond the State Machine
The circuit breaker state machine controls whether requests proceed, but it doesn’t address what happens during a request. When a downstream service becomes latent, threads making calls to that service remain blocked until the timeout expires. In a thread-per-request model, this can exhaust the entire thread pool.
Netflix’s Hystrix addressed this through thread pool isolation. Each dependency gets its own thread pool. When a dependency becomes latent, its pool saturates, but other dependencies remain unaffected. The calling thread (typically a Tomcat request handler) isn’t blocked—it receives an immediate rejection.
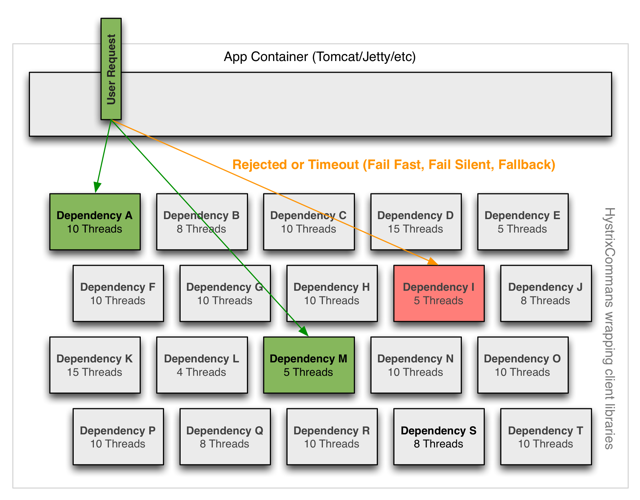
Image source: Netflix Hystrix Wiki
Netflix reported processing 10+ billion Hystrix Command executions per day across their API, with 40+ thread pools per instance. The overhead at the 99th percentile was approximately 9ms—acceptable for network calls that typically take tens to hundreds of milliseconds.
But thread isolation has costs. Each thread pool requires memory for its stack and queue. Context switching adds overhead. For very low-latency operations (in-memory cache lookups), this overhead can exceed the operation’s natural duration.
Hystrix offered an alternative: semaphore isolation. Instead of thread pools, semaphores limit concurrent access to a dependency. No thread switching, no additional queues—but also no timeouts. If the underlying operation hangs, the semaphore slot remains occupied until the operation completes or the caller gives up.
The choice between thread and semaphore isolation depends on the dependency’s characteristics:
| Isolation Type | Memory Overhead | Timeout Support | Best For |
|---|---|---|---|
| Thread Pool | High | Yes | Network calls, untrusted clients |
| Semaphore | Low | No | In-memory operations, trusted clients |
The Half-Open Dilemma: How Many Probes?
When a circuit breaker transitions to half-open, it must decide how many test requests to allow. Too many, and a recovering service might be overwhelmed. Too few, and a healthy service might appear still broken due to transient errors in the small sample.
The permittedNumberOfCallsInHalfOpenState configuration (default: 10 in Resilience4j) determines this. Consider the trade-off:
A single test request provides minimal information. If it fails, the breaker returns to Open—but was it a transient error? If it succeeds, the breaker closes—but the service might only be partially recovered. Ten test requests provide more statistical confidence but create more load on a potentially fragile service.
Some implementations allow gradual recovery. Instead of immediately closing after successful probes, the breaker might increase the permitted number of concurrent requests incrementally. This “ramp-up” period ensures the service can handle increasing load before full traffic resumes.
Fallback Strategies: Graceful Degradation
When a circuit breaker is open, requests don’t just disappear—they need handling. Fallback strategies determine what happens when calls are rejected.
Return Cached Data: Serve stale data from a local cache or a separate cache service. For product catalogs or configuration data, slightly stale information is often acceptable.
Return Default Values: Provide safe defaults. A recommendation service might return an empty list; a user preference service might return standard settings.
Queue for Later Processing: For non-time-sensitive operations, queue the request and process it when the service recovers. This works well for analytics, logging, or eventual-consistency scenarios.
Fail Fast with Clear Error: Sometimes the only honest response is an error. The key is failing quickly—milliseconds instead of seconds—so the caller can make informed decisions.
The critical principle: fallback logic should not depend on the failing service. A fallback that makes another network call to the same dependency defeats the purpose. If a fallback must call an external service, that service should have its own circuit breaker.
sequenceDiagram
participant Client
participant ServiceA
participant CircuitBreaker
participant ServiceB
participant Fallback
Client->>ServiceA: Request
ServiceA->>CircuitBreaker: Call ServiceB
CircuitBreaker->>CircuitBreaker: Check state
alt Circuit Open
CircuitBreaker->>Fallback: Execute fallback
Fallback-->>ServiceA: Cached/Default response
else Circuit Closed
CircuitBreaker->>ServiceB: Forward request
ServiceB-->>CircuitBreaker: Response
CircuitBreaker->>CircuitBreaker: Record outcome
CircuitBreaker-->>ServiceA: Response
end
ServiceA-->>Client: Response
Configuration Trade-offs: The Numbers That Matter
Circuit breaker configuration isn’t about finding “correct” values—it’s about making informed trade-offs based on system characteristics.
Failure Rate Threshold
The failureRateThreshold determines when the breaker trips. A threshold of 50% (Resilience4j default) means the breaker opens when half of recent calls have failed.
Lower thresholds (10-20%) provide faster reaction to problems but increase false positives. A brief network glitch could trip the breaker unnecessarily. Higher thresholds (60-80%) reduce false positives but allow more failed requests through before protection kicks in.
For critical services with well-understood failure modes, lower thresholds make sense. For services with occasional transient failures, higher thresholds prevent over-reaction.
Wait Duration in Open State
The waitDurationInOpenState determines how long the breaker stays open before probing. This should align with the downstream service’s expected recovery time.
If the downstream service typically recovers in 30 seconds, a 60-second wait gives comfortable margin. If recovery takes 5 minutes, a 30-second wait just creates repeated probe failures.
The danger of setting this too short: the breaker enters half-open, the probe fails, and it returns to open. This cycle repeats, creating oscillation without actual recovery. The danger of setting it too long: legitimate requests are rejected for longer than necessary.
Sliding Window Size
The window size affects both responsiveness and statistical significance. A small window (10 calls or 5 seconds) reacts quickly to changes but might trip on noise. A large window (1000 calls or 60 seconds) provides stable measurements but responds slowly to actual problems.
For high-traffic services, count-based windows work well. For services with bursty traffic, time-based windows provide more consistent behavior.
Minimum Number of Calls
This parameter prevents premature tripping during low-traffic periods. Without it, a 100-call window with a 50% threshold would trip after a single failure if only one call had been made.
The trade-off: higher values increase confidence that failures represent a real problem but delay protection during genuine outages. Lower values provide faster protection but risk false positives.
The Hystrix Legacy: Lessons from Netflix
Netflix open-sourced Hystrix in 2012, and it became the de facto standard for circuit breaking in Java ecosystems. By 2018, Netflix announced Hystrix would enter maintenance mode—no new features, only critical bug fixes.
The reasons weren’t that Hystrix was flawed, but that the ecosystem had evolved. The project had achieved its goals: tens of billions of thread-isolated calls per day at Netflix proved the concept. The community had internalized the lessons.
Resilience4j emerged as the preferred successor for several reasons:
-
Lighter Weight: Resilience4j doesn’t require wrapping calls in Command objects. It uses functional composition with decorators.
-
Modular Design: Resilience4j separates concerns into independent modules—CircuitBreaker, Retry, RateLimiter, Bulkhead, TimeLimiter—each usable independently or combined.
-
Native Java 8+: Built for modern Java with lambda support, avoiding legacy patterns.
-
Active Development: Regular updates and community engagement, unlike Hystrix’s frozen state.
The transition from Hystrix to Resilience4j illustrates an important principle: patterns outlive specific implementations. The circuit breaker pattern remains essential; the implementation choice is secondary.
Cascade Failure Antipatterns: What Not to Do
Understanding how circuit breakers help requires understanding what happens without them.
Unbounded Request Acceptance
A service that accepts unlimited incoming requests will eventually queue requests until memory exhausts or thread pools saturate. This is particularly dangerous when downstream latency increases. Each request takes longer, threads remain occupied longer, and the queue grows.
Duo Security experienced this in a 2018 outage: “These queued requests had built up in such a way that the database could not recover as it tried to process this large backlog of requests.”
The fix: limit concurrent requests. A semaphore or bounded queue ensures that under overload, requests fail fast rather than accumulating.
Aggressive Retry Behavior
Square experienced a production incident in March 2017 when a Redis instance became unavailable. The culprit? Code that retried transactions up to 500 times in a tight loop:
const MAX_RETRIES = 500
for i := 0; i < MAX_RETRIES; i++ {
_, err := doServerRequest()
if err == nil {
break
}
}
When the Redis instance failed, every caller hammered it with 500 retries instantly. The fix was reducing retries and adding exponential backoff:
const MAX_RETRIES = 5
const JITTER_RANGE_MSEC = 200
steps_msec := []int{100, 500, 1000, 5000, 15000}
for i := 0; i < MAX_RETRIES; i++ {
_, err := doServerRequest()
if err == nil {
break
}
time.Sleep(time.Duration(steps_msec[i] + rand.Intn(JITTER_RANGE_MSEC)) *
time.Millisecond)
}
Exponential backoff with jitter prevents retry storms—the synchronized retry waves that can DOS a recovering service.
Proximity-Based Failover
When an entire data center fails, where does traffic go? If the answer is “the nearest remaining data center,” you’ve created a domino effect risk.
Consider a system with two US East Coast data centers. If one fails, the other receives roughly double load. If it can’t handle that load, it also fails. Now all traffic shifts to US West Coast, which similarly may fail. Like dominoes, each failure increases load on the remaining capacity.
Geographically distributed systems need either significant overprovisioning (expensive) or intelligent load distribution that considers available capacity, not just proximity.
Circuit Breakers in the Broader Resilience Toolkit
Circuit breakers don’t operate in isolation. They’re part of a resilience pattern palette:
Timeout: Limits how long a request can wait. Prevents indefinite blocking but doesn’t reduce request volume during failures.
Retry: Attempts failed operations again. Useful for transient failures but can amplify load during sustained outages.
Bulkhead: Isolates components so failure in one doesn’t propagate. Thread pools are a bulkhead implementation.
Rate Limiter: Controls request volume. Prevents overload but doesn’t distinguish between healthy and failing downstream services.
Circuit Breaker: Combines monitoring and protection. Detects sustained failures and stops requests entirely.
These patterns compose. A typical configuration might:
- Wrap a call with a circuit breaker
- Apply a timeout inside the breaker
- Add a bulkhead to limit concurrent calls
- Implement retry with exponential backoff (for transient failures)
- Provide a fallback for when the breaker is open
The order matters. Retry should typically wrap circuit breaker, not vice versa—retry amplifies load, so it should respect the circuit breaker’s decision to stop calling.
The Production Reality: Observability is Non-Negotiable
A circuit breaker without observability is a hidden point of failure. When a breaker trips unexpectedly, operators need to know. When a breaker refuses to close, engineers need to investigate.
Modern implementations expose metrics and events:
- State transitions (Closed → Open → Half-Open)
- Current failure and slow call rates
- Number of rejected calls
- Time in current state
Resilience4j provides an event stream for each circuit breaker:
circuitBreaker.getEventPublisher()
.onStateTransition(event -> log.info("State change: {}", event))
.onError(event -> log.warn("Call failed: {}", event))
.onSuccess(event -> metrics.recordSuccess(event.getElapsedDuration()));
These metrics feed into monitoring dashboards and alerting systems. A circuit breaker that trips frequently indicates a downstream problem. A circuit breaker that stays permanently open indicates either a persistent downstream failure or misconfigured thresholds.
When Circuit Breakers Fail
Circuit breakers aren’t silver bullets. They can fail in several ways:
Stuck Open: A breaker remains open long after the downstream service has recovered. Usually caused by misconfigured wait duration or a lack of automatic transition from Open to Half-Open.
Stuck Closed: A breaker fails to trip despite sustained failures. Often due to minimum call thresholds that aren’t met during low-traffic periods.
Oscillation: A breaker rapidly cycles between states, never stabilizing. Typically caused by half-open probe failures due to insufficient recovery time or probe requests hitting still-unhealthy endpoints.
Cascading Through Fallbacks: When fallback logic itself depends on failing services, the protection becomes a liability. Each fallback should be analyzed for its own dependencies.
The remedy for all these: observability and testing. Chaos engineering practices—deliberately injecting failures—reveal whether circuit breakers behave as expected under actual failure conditions.
The Deeper Lesson: Embracing Failure
Circuit breakers embody a fundamental shift in how we think about distributed systems. We can’t prevent failures—we can only control how they propagate.
The DynamoDB outage of 2015 wasn’t caused by a lack of redundancy. The metadata service was replicated across data centers. What failed was the system’s response to latency: retries that amplified load rather than backing off.
The circuit breaker pattern accepts that services will fail. It asks: when failure occurs, do we want our system to degrade gracefully or collapse entirely? The pattern provides the mechanism for graceful degradation: fail fast, protect downstream resources, and probe for recovery.
This philosophy extends beyond technical implementation. It’s about designing systems that acknowledge the inherent unreliability of networks, hardware, and software. A service without circuit breakers isn’t robust—it’s fragile in ways that won’t be visible until the moment they matter.
References
-
Nolan, L. (2020). “How to Avoid Cascading Failures in Distributed Systems.” InfoQ. https://www.infoq.com/articles/anatomy-cascading-failure/
-
Netflix. (2012). “Introducing Hystrix for Resilience Engineering.” Netflix TechBlog. http://techblog.netflix.com/2012/11/hystrix.html
-
Netflix. “How it Works.” Hystrix Wiki. https://github.com/Netflix/Hystrix/wiki/How-it-Works
-
Resilience4j. “CircuitBreaker Documentation.” https://resilience4j.readme.io/docs/circuitbreaker
-
Microsoft. (2025). “Circuit Breaker Pattern.” Azure Architecture Center. https://learn.microsoft.com/en-us/azure/architecture/patterns/circuit-breaker
-
Fowler, M. (2014). “Circuit Breaker.” https://martinfowler.com/bliki/CircuitBreaker.html
-
Nygard, M. T. (2007). Release It!: Design and Deploy Production-Ready Software. Pragmatic Bookshelf.
-
Ulrich, M. “Addressing Cascading Failures.” In Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media.
-
AWS. (2015). “Summary of the AWS Service Event in the Northern Virginia (US-EAST-1) Region.” AWS Service Health Dashboard.
-
Grab Engineering. (2023). “Sliding Window Rate Limits in Distributed Systems.” https://engineering.grab.com/frequency-capping
-
Quickbooks Engineering. (2020). “Resiliency: Two Alternatives for Fault Tolerance to Deprecated Hystrix.” https://quickbooks-engineering.intuit.com/resiliency-two-alternatives-for-fault-tolerance-to-deprecated-hystrix-de58870a8c3f
-
Wikipedia. “Circuit Breaker Design Pattern.” https://en.wikipedia.org/wiki/Circuit_breaker_design_pattern