Imagine you’re running a service with 10 servers, each capable of handling 1,000 requests per second. You set up a round-robin load balancer—simple, elegant, fair. Every server gets its turn in sequence. Traffic flows smoothly until suddenly, at 2 AM, your monitoring alerts start screaming. Half your servers are overwhelmed, queues are growing, latencies are spiking, and the other half of your servers are nearly idle.
What went wrong?
The servers weren’t identical. Three of them were newer machines with faster CPUs and more memory. Three were legacy boxes running older hardware. The round-robin algorithm, in its mechanical fairness, sent exactly the same number of requests to a struggling legacy server as it did to a powerful new one. The legacy servers couldn’t keep up, requests piled up in their queues, and eventually they started timing out—cascading into a partial outage that woke up half your engineering team.
This isn’t a hypothetical scenario. It’s a pattern that has played out across countless production systems, from startups to enterprises. The culprit isn’t usually a bug—it’s a fundamental misunderstanding of what load balancing algorithms actually do, and more importantly, what they don’t do.
The False Comfort of Simplicity
Round robin remains one of the most widely deployed load balancing strategies, and for good reason. It’s trivial to implement: maintain a counter, increment it modulo the number of servers, and route each request to the server at that index. The implementation fits in a handful of lines of code. The mental model is intuitive—everyone gets an equal share.
But simplicity comes at a cost. Round robin operates on a single assumption: all servers are equal. This assumption is rarely true in practice.
Even in a homogeneous cluster—where every server has identical hardware—performance can vary dramatically. A server might be experiencing higher memory pressure due to a memory leak. Another might be running background jobs that consume CPU. A third might have accumulated more TCP connections because previous requests took longer to complete. Round robin is oblivious to all of this. It will happily send the next request to a server that’s gasping for resources.
The problem compounds under variable request durations. In many real-world applications, request processing times follow a heavy-tailed distribution. Some requests complete in milliseconds; others take seconds or even minutes. A server that happened to receive several long-running requests will have a growing queue, but round robin will continue sending it new requests at exactly the same rate as the idle servers.

Image source: Quastor Blog
The Random Selection Problem
Before dismissing random selection as obviously inferior, consider that it’s the foundation for many sophisticated load balancing algorithms. Uniform random selection gives you asymptotic fairness—over a million requests, each server will receive approximately the same number. The problem is in the “approximately.”
If you place one million balls into one thousand bins using uniform random selection, the Central Limit Theorem tells us the distribution will be normal. Most bins will have around 1,000 balls, but some will have 900, others 1,100. That’s a 20% variance from the mean, which translates directly to load imbalance.
The issue becomes more acute when you consider the temporal dimension. At any given moment during the allocation process, one bin might have dozens more balls than another. In load balancing terms, this means some servers could be processing significantly more concurrent requests than others, even though the long-term averages even out.
Michael Mitzenmacher’s seminal work at Harvard demonstrated that random selection produces a maximum load of approximately $O(\frac{\log n}{\log \log n})$ times the average when placing $n$ balls into $n$ bins. This logarithmic factor might seem academic, but in systems handling millions of requests per second, it manifests as real latency variance and queue depth imbalance.
Dynamic Algorithms: Enter Least Connections
The obvious improvement is to make the algorithm aware of server state. Least connections does exactly what its name suggests: route each new request to the server with the fewest active connections. This is a dynamic algorithm—it adapts to real-time conditions.
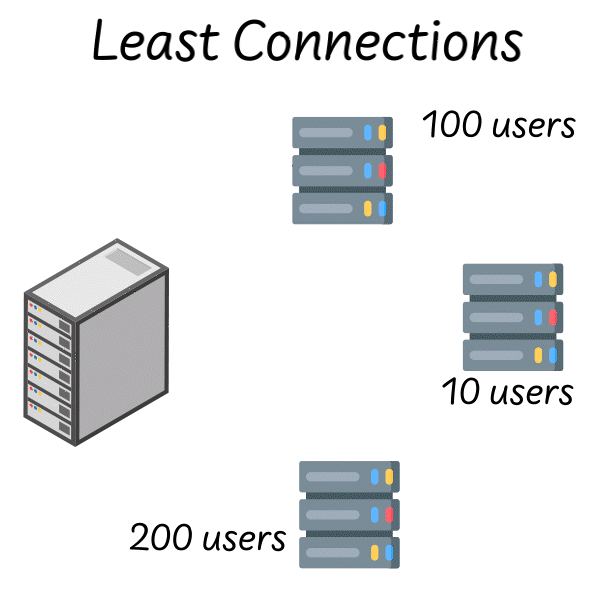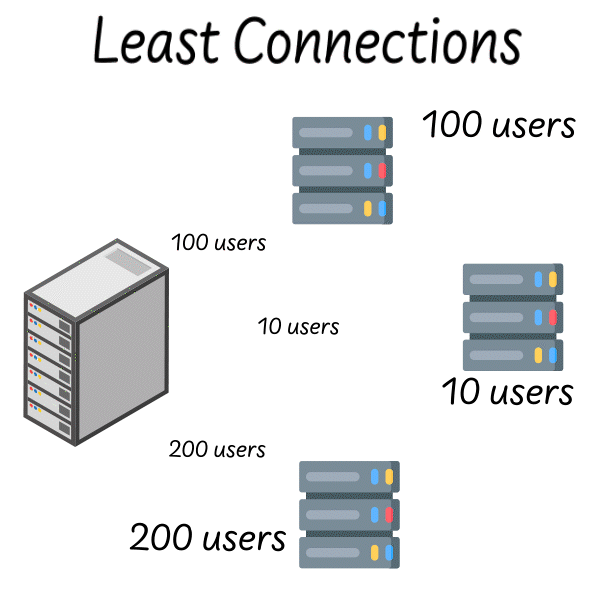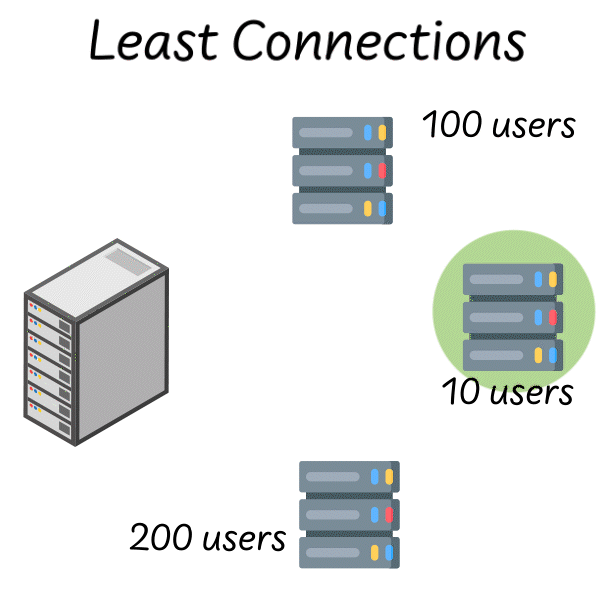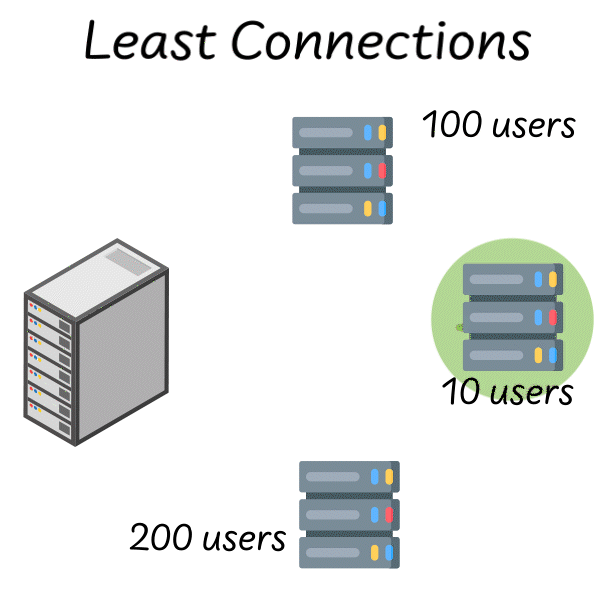
Image source: Quastor Blog
In theory, this should solve the round-robin problem. If a server is struggling, its connection count will grow, and the load balancer will naturally route traffic elsewhere. If a server is fast, its connections complete quickly, and it receives more new requests.
The challenge is implementation complexity. The load balancer must maintain accurate counts of active connections for every server. It must update these counts atomically as connections open and close. It must handle edge cases like connection timeouts, health check failures, and server additions or removals.
There’s also a subtler problem: herding behavior. When a new server joins the cluster, it has zero connections. Every load balancer instance sees this and immediately starts routing traffic to it. The new server can become overwhelmed before it has a chance to warm up. This is related to—but distinct from—the classic thundering herd problem, where multiple clients simultaneously react to the same event.
The Power of Two Random Choices
In 1999, Yossi Azar and colleagues published a result that would reshape how we think about load balancing. Their finding was elegant: instead of choosing one random server, choose two random servers and send the request to the one with fewer connections.
This simple modification—the “power of two random choices”—produces an exponential improvement. While random selection gives you $O(\frac{\log n}{\log \log n})$ maximum load, power of two choices achieves $O(\log \log n)$. For a system with one million servers, this is the difference between a maximum load of roughly 6 versus roughly 4,000 relative to the average.
The intuition is probabilistic. When you pick one random server, there’s a chance you’ll pick an overloaded one. When you pick two, you only send to the more loaded one if both are loaded. The probability of both being heavily loaded drops dramatically—specifically, it drops with the square of the individual probability.
graph TD
A[Incoming Request] --> B[Pick Random Server 1]
A --> C[Pick Random Server 2]
B --> D{Compare Load}
C --> D
D -->|Server 1 has fewer connections| E[Route to Server 1]
D -->|Server 2 has fewer connections| F[Route to Server 2]
Consider a concrete example. You have 10 servers, and server 1 already has one ball while others are empty. With random selection, there’s a 10% chance you’ll make server 1 even more imbalanced. With power of two choices, you’d need to pick server 1 on both draws—probability $\frac{1}{10} \times \frac{1}{9} \approx 1.1\%$. That’s nearly a 10x reduction in the probability of making a bad decision.
The improvement becomes more dramatic as you consider cascading effects. To reach a state where one server has three more balls than the minimum, random selection needs just three consecutive unlucky draws: probability $\frac{1}{1000}$. With power of two choices, the probability of the shortest path to that state is approximately $0.0000054$—over 180 times smaller.
This is why Envoy’s default load balancer implementation uses power of two choices rather than scanning all servers for the true minimum. The marginal improvement from choosing among more than two servers is negligible, while the computational cost scales linearly with the number of choices.
Weighted Algorithms: Handling Heterogeneous Clusters
Real clusters are rarely homogeneous. You might have a mix of instance types, or servers at different stages of their lifecycle with varying resource availability. This is where weighted algorithms become essential.
Weighted round robin assigns each server a weight proportional to its capacity. A server with weight 3 receives three requests for every one request sent to a server with weight 1. The implementation typically uses a smooth weighted round robin algorithm that avoids batching—instead of sending 3 consecutive requests to the weighted server, it interleaves them naturally.
The limitation of weighted round robin is the same as regular round robin: weights are static. If a powerful server starts experiencing issues—a failing disk, network congestion, or a noisy neighbor—the load balancer won’t adjust. It will continue sending the same proportion of traffic.
Weighted least connections combines the benefits of both approaches. It uses weights as baseline preferences but adjusts dynamically based on actual connection counts. The implementation typically normalizes connection counts by server weight, so a server with weight 2 is considered “less loaded” with 20 connections than a server with weight 1 with 15 connections.
Consistent Hashing: When State Matters
Some applications require session affinity—consecutive requests from the same client must reach the same server. This might be because the server maintains in-memory session state, caches user-specific data, or maintains WebSocket connections.
Consistent hashing provides a solution that’s both stateful and resilient to server changes. Instead of hashing requests directly to server indices, you hash both servers and requests to positions on a virtual ring. Each request is served by the first server encountered moving clockwise from the request’s position.
The elegance of consistent hashing is in how it handles server additions and removals. When a server is added, it only takes over requests that hash to positions between it and the previous server on the ring—typically $\frac{1}{n}$ of all requests for $n$ servers. When a server fails, its load is distributed to the next server on the ring, not redistributed across the entire cluster.
The trade-off is that consistent hashing can produce uneven load distribution, especially with small clusters or poorly distributed hash functions. Production implementations typically use virtual nodes—each physical server appears at multiple positions on the ring—to smooth out the distribution.
Real-World Failure: The Atlassian Incident
In 2019, Atlassian experienced a significant outage that traced back to load balancer misconfiguration during a blue-green deployment. The incident illustrates how load balancing algorithms interact with broader system design choices.
The deployment introduced new servers to replace existing ones. However, the new servers were inadequately provisioned—they ran out of memory shortly after starting to handle traffic. The load balancer’s health checks focused on application-level responses but didn’t detect the underlying resource exhaustion.
A more sophisticated load balancing setup might have mitigated this. Least response time algorithms would have naturally deprioritized the struggling servers as their latencies increased. Power of two choices would have probabilistically reduced traffic to them as their connection counts grew. But the configuration used a simpler approach that couldn’t adapt to the unexpected failure mode.
The incident also highlighted the importance of health check design. A health check that only verifies “is the application process running?” won’t catch a server that’s technically alive but severely degraded. Effective health checks should verify response latency, resource utilization, and dependency connectivity.
Choosing the Right Algorithm
There’s no universal best choice—each algorithm optimizes for different constraints:
Round Robin excels when you have homogeneous servers, predictable request durations, and want minimal overhead. It’s the right default for many applications.
Weighted Round Robin handles heterogeneous clusters where server capacities are known and stable. It’s appropriate when you’ve provisioned different instance types and want to maximize utilization.
Least Connections adapts to variable workloads and can handle heterogeneous servers without explicit weights. It’s ideal when request durations vary widely and you want automatic load distribution.
Power of Two Choices offers a sweet spot between simplicity and effectiveness. It provides near-optimal load distribution with minimal overhead—just two random selections and a comparison. It’s particularly effective in distributed systems where maintaining accurate global state is expensive.
Consistent Hashing is necessary when you need session affinity or are working with cached data. The trade-off is potentially uneven distribution and slightly more complex implementation.
In practice, many production systems use hybrid approaches. A load balancer might use consistent hashing for stateful requests, power of two choices for stateless requests, and health checks that consider both application responses and resource metrics.
The Mathematics in Practice
The theoretical improvements from power of two choices translate directly to real-world performance. Envoy’s simulations show that with heterogeneous servers—some fast, some slow—round robin produces distinctly bimodal queue depths: the slow servers accumulate deep queues while fast servers sit nearly idle. Power of two choices smooths this out, maintaining comparable queue depths across all servers regardless of their individual speeds.
This has practical implications for tail latency. A system’s p99 latency is often determined by its most loaded server. If 1% of requests hit an overloaded server with a deep queue, those requests will experience significantly higher latency. By preventing any single server from becoming severely overloaded, power of two choices reduces tail latency variance across the cluster.
The algorithm also scales gracefully. As you add more servers, the probability of any single server becoming overloaded decreases further. This is particularly valuable in auto-scaling environments where cluster size fluctuates based on demand.
Implementation Considerations
Implementing power of two choices in a production load balancer requires care. The random selection must be truly random—using a predictable pseudo-random number generator can inadvertently create patterns. The comparison of server loads must be atomic; racing updates can lead to incorrect decisions.
Many implementations use a variation called “least request” where the load balancer tracks pending requests rather than active connections. This is often a better proxy for server load in HTTP/2 environments where connections are multiplexed.
The algorithm also needs to handle edge cases: what if both selected servers are unhealthy? What if there’s only one healthy server? What if a server is added or removed mid-selection? Production implementations typically fall back to simpler strategies when edge cases are detected.
Load balancing algorithms aren’t just implementation details—they’re fundamental architectural decisions that affect system performance, reliability, and cost. The difference between random selection and power of two choices isn’t academic; it’s the difference between a system that degrades gracefully under load and one that experiences cascading failures.
The key insight from decades of research is that small algorithmic changes can produce outsized effects. Adding a second random choice—just one more “roll of the dice”—transforms a $O(\log n)$ problem into an $O(\log \log n)$ one. In a world where systems routinely handle millions of requests, those logarithms matter.
When designing or configuring load balancing for your systems, look beyond the default. Understand your workload characteristics, your server heterogeneity, and your failure modes. Choose algorithms that match your constraints, not just ones that are easy to implement. And remember: fair doesn’t mean equal. A truly fair load balancer sends more work to servers that can handle it, and less to those that can’t.
References
- Mitzenmacher, M. (2001). The Power of Two Choices in Randomized Load Balancing. IEEE Transactions on Parallel and Distributed Systems.
- Azar, Y., et al. (1999). Balanced Allocations. Proceedings of the 26th ACM Symposium on Theory of Computing.
- Envoy Proxy Documentation. Load Balancing. envoyproxy.io
- Cloudflare Learning Center. Types of load balancing algorithms. cloudflare.com
- Peterson, L., & Davie, B. Computer Networks: A Systems Approach. Morgan Kaufmann.