In late 2017, a Reddit user with the handle “deepfakes” posted a video that would fundamentally change how we think about visual evidence. The clip showed a celebrity’s face seamlessly mapped onto another person’s body. It wasn’t the first time someone had manipulated video, but the quality was unprecedented—and the software to create it was soon released as open-source code. Within months, the term “deepfake” had entered the lexicon, representing a collision of deep learning and deception that continues to evolve at a startling pace.
The implications extend far beyond entertainment. In 2019, a UK-based energy company’s CEO received a call from what sounded like his boss, the parent company’s chief executive, instructing him to transfer €220,000 to a Hungarian bank account. The voice was an audio deepfake. The money vanished. By 2023, deepfake fraud attempts had surged by 3,000%, and cybersecurity firms estimate synthetic media fraud could reach $40 billion in losses globally.
But understanding deepfakes requires looking past the headlines and into the neural architectures that make them possible.
The Neural Network Behind the Mask
At their core, deepfakes rely on a family of neural network architectures that have evolved significantly since 2017. The original approach used autoencoders—neural networks designed to compress data into a compact representation and then reconstruct it.
An autoencoder consists of two parts: an encoder that reduces an input image to a lower-dimensional “latent space” representation, capturing essential features like facial structure and expression, and a decoder that reconstructs the image from this compressed form. The deepfake trick involves training two decoders—one for the source face and one for the target—while sharing a single encoder.

Image source: AI Summer
When you feed the target person’s face through the encoder, it produces a latent representation of their expression and pose. But instead of using their decoder, you use the source person’s decoder. The result: the source’s facial identity gets mapped onto the target’s expressions and movements.
The approach worked, but early results were often blurry and unconvincing. That changed with the integration of Generative Adversarial Networks (GANs), first introduced by Ian Goodfellow in 2014.
Enter the Adversary
GANs introduced a fundamentally different approach to synthetic media. Instead of a single network learning to reproduce images, GANs pit two neural networks against each other in what researchers call a “minimax game.”
A generator network creates images from random noise, attempting to produce outputs indistinguishable from real photos. A discriminator network evaluates these outputs, learning to classify images as real or fake. The two networks train simultaneously: the discriminator improves at spotting fakes, while the generator improves at fooling the discriminator.
$$\min_G \max_D V(D,G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log(1 - D(G(z)))]$$This adversarial training produces sharper, more realistic outputs than autoencoders alone. When researchers attached GANs to the decoder portion of autoencoder architectures, deepfake quality improved dramatically.
The breakthrough came with StyleGAN, introduced by NVIDIA researchers in 2019. StyleGAN’s key innovation was a “mapping network” that transforms the input latent vector into an intermediate latent space W, which then controls the “style” of the generated image at different scales through adaptive instance normalization (AdaIN).

Image source: AI Summer
This architecture allows fine-grained control over generated images. Coarse styles control pose and face shape. Middle styles govern facial features. Fine styles determine color and micro-details. The result: synthetic faces so convincing that humans can barely distinguish them from real photographs.
The Detection Challenge
As deepfake creation tools proliferated, so did efforts to detect them. The Deepfake Detection Challenge (DFDC), launched in 2019 by a consortium including Facebook, Microsoft, and AWS, offered $1 million in prizes. Over 2,000 teams submitted entries. The winning model achieved 65.18% accuracy on a held-out test set—a sobering result that highlighted just how difficult detection had become.
Detection methods fall into several categories:
Visual Artifact Analysis: Early deepfakes left telltale signs—flickering around face edges, inconsistent blinking patterns, or misaligned teeth. The lip-syncing artifacts were particularly telling. A 2024 method called LIPINC (LIP-syncing detection based on mouth INConsistency) achieves around 95% accuracy in detecting lip-syncing deepfakes by analyzing temporal inconsistencies between audio and mouth movements.
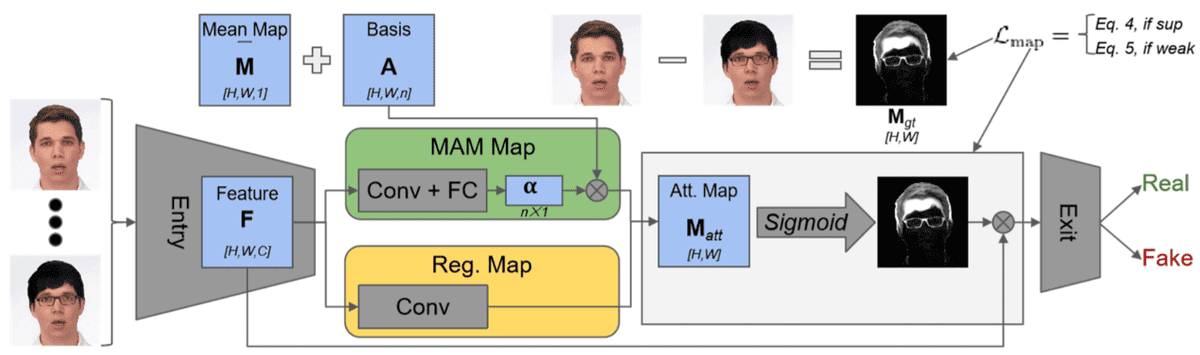
Image source: AI Summer
Biological Signal Detection: Researchers discovered that real faces exhibit subtle color changes from blood flow—visible through remote photoplethysmography (rPPG). The technique measures minute variations in skin color caused by the cardiac cycle. Early deepfakes couldn’t reproduce these signals, making rPPG a reliable detection method. But a 2025 study published in Frontiers in Imaging found that modern high-quality deepfakes can inadvertently preserve heartbeat patterns from source videos, complicating this approach.
Frequency Domain Analysis: Deepfakes often leave distinct signatures in the frequency domain. When images are transformed using Discrete Cosine Transform (DCT) or Fourier analysis, synthetic faces show abnormal high-frequency patterns invisible to human eyes. A 2024 study achieved 88.52% mean Average Precision using frequency-domain features.
Convolutional Neural Network Classifiers: Deep learning detectors like Xception and MesoNet have shown strong results. Xception, which uses depthwise separable convolutions, achieved accuracy levels as high as 99.65% on controlled datasets. However, performance typically degrades significantly on real-world data outside the training distribution.
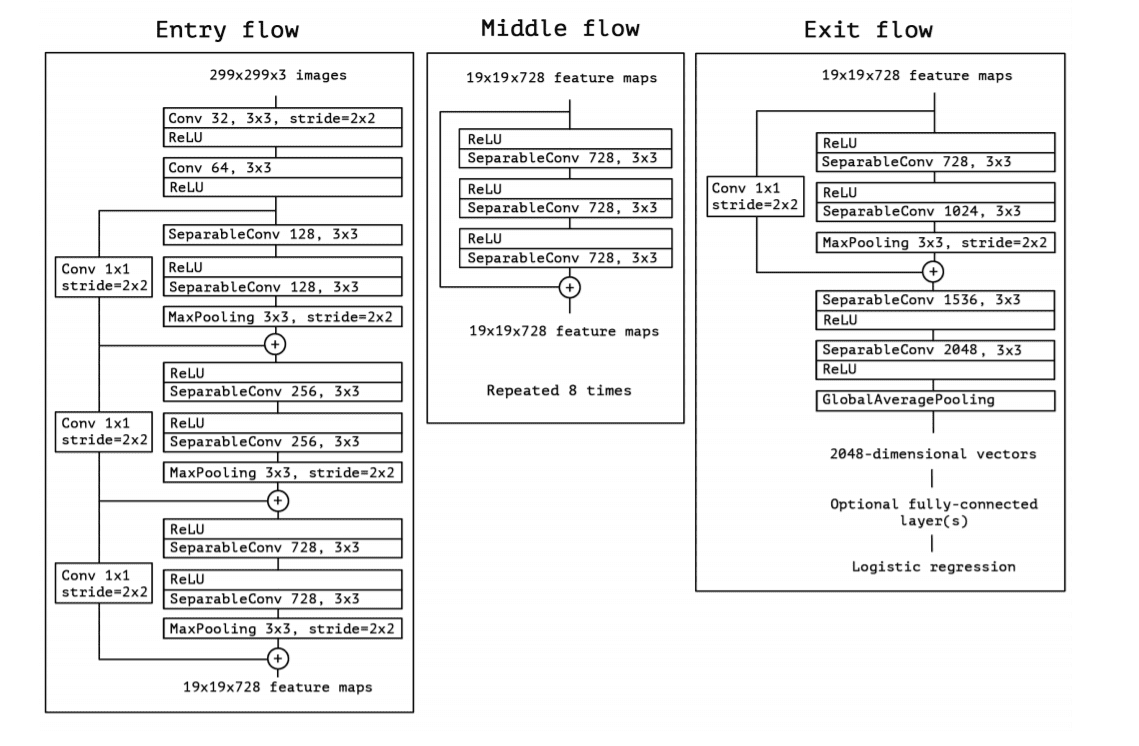
Image source: AI Summer
The Arms Race Intensifies
Here’s the fundamental problem: every improvement in detection can be used to improve generation. If a discriminator learns to spot unnatural blinking patterns, that knowledge can inform the next generation of deepfake generators.
This adversarial dynamic creates a perpetual arms race. Researchers at the University at Buffalo developed a tool that identifies deepfakes by analyzing light reflections in the eyes. Real eyes show consistent reflections; deepfakes often don’t. But within months, newer generation models were producing more accurate eye reflections.
The rise of diffusion models has added another dimension to this competition. While GANs remain dominant for face swapping, diffusion models offer a different approach to synthetic media generation—iteratively denoising random data into coherent images. Models like Stable Diffusion can generate entirely synthetic faces without any source photographs, raising new challenges for detection.
From Deepfakes to Detection Tools
For individuals and organizations trying to identify synthetic media, several practical approaches exist:
Manual Inspection: Look for inconsistent lighting, unnatural skin textures, irregular pupil sizes, or objects passing behind faces that cause distortion. Pay particular attention to teeth (often poorly rendered) and the edges of faces during movement.
Browser Extensions: Tools like Deepfake Detector and BitMind’s Chrome extension analyze media in real-time, flagging potential manipulations. These tools use lightweight models that trade some accuracy for speed.
Content Provenance: The Coalition for Content Provenance and Authenticity (C2PA) has developed an open standard for embedding verifiable metadata into media files. Digital signatures attached at the point of creation can prove whether an image or video has been modified.
However, all detection methods share a critical limitation: they work best on deepfakes created with known techniques. Novel architectures, or even simple post-processing like compression or color adjustment, can foil many detectors.
The Regulatory Landscape
Governments have begun responding to the deepfake threat. The European Union’s AI Act, which entered into force in August 2024, introduces transparency requirements for synthetic media. Deepfakes must be labeled as such, and providers of AI systems that generate synthetic content must ensure outputs are “machine-readable and detectable as artificially generated or manipulated.”
In the United States, the TAKE IT DOWN Act, signed into law in May 2025, criminalizes the publication of non-consensual intimate imagery, including AI-generated content. Several states have enacted additional legislation targeting deepfakes used in elections or fraud.
But regulation faces enforcement challenges. Deepfake creation tools are now freely available, running on consumer hardware. The software doesn’t respect borders, and attribution—proving who created a particular deepfake—remains technically difficult.
What Comes Next
The trajectory of deepfake technology points toward increasing sophistication and accessibility. In 2023, there were roughly 500,000 deepfake videos online. By 2025, estimates suggest that number has grown to over 8 million. The barrier to entry has collapsed; creating a convincing face swap once required hours of training on expensive hardware. Now, web-based tools can produce results in minutes.
Voice cloning has followed a similar path. Modern systems can clone a voice from just 3-5 seconds of audio, capturing not just timbre but speaking patterns and emotional inflections. The combination of synthetic video and audio—multimodal deepfakes—presents detection challenges that neither modality alone poses.
Research continues on both sides of the arms race. Detection methods incorporating multimodal analysis, temporal coherence checks, and biological signal verification show promise. But the fundamental asymmetry remains: it’s easier to create convincing fakes than to reliably detect them.
The implications extend beyond fraud and misinformation. When any video can be fabricated, the value of video evidence—in courts, journalism, and personal relationships—becomes suspect. The philosopher’s concept of “epistemic threat” has become a practical concern.
Understanding how deepfakes work—the autoencoders, GANs, and diffusion models that power them—doesn’t solve the problem. But it provides the foundation for critical evaluation of visual media. In a world where seeing is no longer believing, technical literacy becomes a form of self-defense.
References
-
Wikipedia contributors. “Deepfake.” Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/wiki/Deepfake
-
Goodfellow, I., et al. (2014). “Generative Adversarial Nets.” Advances in Neural Information Processing Systems. https://arxiv.org/abs/1406.2661
-
Karras, T., Laine, S., & Aila, T. (2019). “A Style-Based Generator Architecture for Generative Adversarial Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://arxiv.org/abs/1812.04948
-
Rössler, A., et al. (2019). “FaceForensics++: Learning to Detect Manipulated Facial Images.” Proceedings of the IEEE International Conference on Computer Vision. https://arxiv.org/abs/1901.08971
-
Dolhansky, B., et al. (2020). “The DeepFake Detection Challenge (DFDC) Dataset.” arXiv preprint. https://arxiv.org/abs/2006.07397
-
Afchar, D., et al. (2018). “MesoNet: a Compact Facial Video Forgery Detection Network.” IEEE International Workshop on Information Forensics and Security. https://arxiv.org/abs/1809.00888
-
Chollet, F. (2017). “Xception: Deep Learning with Depthwise Separable Convolutions.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. https://arxiv.org/abs/1610.02357
-
DeepStrike (2025). “Deepfake Statistics 2025: AI Fraud Data & Trends.” https://deepstrike.io/blog/deepfake-statistics-2025
-
Frontiers in Imaging (2025). “High-quality deepfakes have a heart!” https://www.frontiersin.org/journals/imaging/articles/10.3389/fimag.2025.1504551/full
-
C2PA. “Coalition for Content Provenance and Authenticity.” https://c2pa.org/
-
European Parliament. “EU AI Act: first regulation on artificial intelligence.” https://www.europarl.europa.eu/topics/en/article/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence
-
Matern, F., et al. (2019). “Exploiting Visual Artifacts to Expose Deepfakes and Face Manipulations.” IEEE Winter Applications of Computer Vision Workshops.