In the late 1970s, Jim Gray and his colleagues at IBM Research were working on transaction processing systems that needed to guarantee data integrity even when power failed mid-operation. His solution was elegant in its simplicity: never write data to the main store until you’ve first written it to a log. This principle, formalized in his 1981 paper “The Transaction Concept: Virtues and Limitations,” became known as Write-Ahead Logging, and decades later, it remains the foundation of every major database system.
Consider what happens when you commit a transaction. The database acknowledges success to your application, but what has actually been written to disk? In most systems, the answer is surprising: almost nothing. The modified data pages sit in memory, waiting to be flushed later. Your transaction’s durability rests entirely on a separate append-only file—the Write-Ahead Log.
The Buffer Pool Problem
Databases don’t write directly to disk for every operation. That would be catastrophically slow. Instead, they maintain a buffer pool—a cache of data pages in memory where all reads and writes occur. When you update a row, the database modifies the page in the buffer pool and marks it “dirty.” The actual disk write happens asynchronously, often seconds or minutes later.
This architecture creates a fundamental tension. On one hand, keeping dirty pages in memory as long as possible maximizes performance. On the other hand, those pages represent uncommitted state—if the system crashes, they’re lost forever. How can a database guarantee durability while simultaneously delaying writes?
The answer lies in two policy decisions that shape everything about recovery: STEAL and FORCE.
STEAL: Can Uncommitted Data Go to Disk?
A STEAL policy allows the buffer manager to write dirty pages to disk even before their transaction commits. This is essential for performance—if the buffer pool fills up with dirty pages from long-running transactions, the database would stall without the ability to evict them.
But STEAL creates a problem: the disk now contains changes from transactions that might never commit. If those transactions abort, the database must somehow undo those changes. This requires UNDO information—records of what the data looked like before the modification.
FORCE: Must All Changes Hit Disk Before Commit?
A FORCE policy requires that every modified page be written to disk before the transaction is considered committed. This provides durability without any recovery mechanism—the data is already safe on disk when the commit returns.
But FORCE is expensive. A transaction touching 100 pages scattered across the disk would require 100 random I/O operations before returning. The latency would be unacceptable for any real workload.
Most databases choose STEAL/NO-FORCE. They allow uncommitted writes to disk (STEAL) and don’t require data pages to be flushed before commit (NO-FORCE). This combination delivers excellent performance but introduces complexity: the database must be able to both UNDO uncommitted changes and REDO committed changes that never made it to disk.
The WAL Protocol
Write-Ahead Logging solves the STEAL/NO-FORCE problem with a deceptively simple rule: log records must be written to stable storage before the corresponding data pages.
When a transaction modifies a page, the database doesn’t write the page to disk. Instead, it writes a log record describing the change. This record contains:
- The transaction identifier
- The page being modified
- The before-image (for UNDO)
- The after-image (for REDO)
- A Log Sequence Number (LSN) that uniquely identifies this record
The LSN becomes the key that ties everything together. Every data page stores the LSN of the most recent log record that modified it (pageLSN). The system tracks the highest LSN successfully flushed to disk (flushedLSN). A page can only be written to disk when its pageLSN <= flushedLSN—ensuring the log record exists before the data.

Image source: sookocheff.com - Write-ahead logging and the ARIES crash recovery algorithm
The commit operation itself is elegantly simple. The database writes a COMMIT record to the log, flushes the log to disk, and returns success to the application. The data pages might not be written for minutes. But if the system crashes, the log contains everything needed to recreate the transaction’s effects.
ARIES: The Industry-Standard Recovery Algorithm
In 1992, researchers at IBM Almaden published ARIES (Algorithms for Recovery and Isolation Exploiting Semantics), which became the blueprint for crash recovery in virtually every commercial database. ARIES implements WAL with three phases that systematically restore the database to a consistent state.
Analysis Phase
The recovery process begins at the last checkpoint—a snapshot of system state written periodically during normal operation. The analysis phase scans forward through the log, building two tables:
- Dirty Page Table (DPT): Pages that were modified but may not have been written to disk
- Active Transaction Table (ATT): Transactions that were running at the time of crash
For each log record, the analysis updates these tables. When it encounters a COMMIT or ABORT record, it removes that transaction from the ATT. When it encounters an UPDATE record, it adds the page to the DPT if not already present.
Redo Phase
This is where ARIES reveals its insight: it redoes ALL changes from the appropriate starting point, not just committed transactions. The algorithm replays the log forward from the oldest LSN in the DPT, applying every modification regardless of transaction status.
This seems wasteful—why redo changes that will later be undone? The answer is correctness. By replaying the entire log, ARIES restores the database to exactly the state it was in at the moment of crash. This simplifies the algorithm dramatically.
For each update record, ARIES checks:
- Is the page in the DPT?
- Does the record’s LSN exceed the page’s
recLSN? - Does the page’s current
pageLSNfall below the record’s LSN?
Only if all three conditions hold does ARIES apply the change. This prevents re-applying changes that were already flushed to disk before the crash.
Undo Phase
Finally, ARIES reverses all changes made by transactions that never committed. It processes the ATT—the transactions still active at crash time—and walks backward through their log records, applying inverse operations.
Crucially, ARIES writes new log records for these undo operations. These Compensation Log Records (CLRs) ensure that if the system crashes during recovery, the undo process can resume from where it left off rather than starting over.
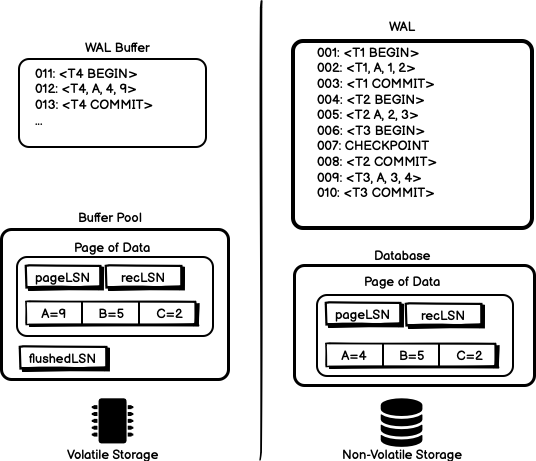
Image source: sookocheff.com - Write-ahead logging and the ARIES crash recovery algorithm
Real-World Implementations
PostgreSQL: Sequential Segments
PostgreSQL’s WAL implementation divides the log into 16 MB segment files stored in the pg_wal directory. Each segment accumulates log records sequentially, and PostgreSQL recycles old segments after they’re no longer needed for recovery.
The key innovation in PostgreSQL is how it handles the fsync cost. Writing to the WAL requires an fsync before commit—that’s the durability guarantee. But fsync is expensive, often taking milliseconds. PostgreSQL uses group commit to amortize this cost: when multiple transactions commit simultaneously, they share a single fsync operation.
A configuration parameter commit_delay (default 0) specifies how many microseconds the server should wait for other transactions before flushing. Combined with commit_siblings (default 5), which sets the minimum concurrent transactions needed to trigger the delay, PostgreSQL can batch multiple commits into a single I/O operation.
MySQL InnoDB: The Doublewrite Buffer
MySQL’s InnoDB storage engine adds an interesting twist to WAL: the doublewrite buffer. This addresses a problem specific to partial page writes.
If the system crashes while writing a 16 KB page to disk, only part of the page might make it. The remaining portion contains garbage, and the page is corrupted. WAL alone cannot fix this—the REDO record describes a change to a page, but if the base page is corrupt, applying the change produces corrupt data.
InnoDB’s solution writes each page twice: first to a dedicated doublewrite buffer area, then to its final location. On recovery, InnoDB checks for partially written pages in the doublewrite buffer. If found, it copies the complete version to the main storage before proceeding with normal WAL recovery.
This doubles the write workload for data pages, but the doublewrite buffer is written sequentially, making it much faster than random page writes. For workloads sensitive to write amplification, the doublewrite buffer can be disabled—but only if you’re confident in your power infrastructure.
SQLite: WAL Mode vs. Rollback Journal
SQLite offers two approaches to durability, and the choice reveals the tradeoffs in WAL design.
The traditional rollback journal writes a copy of the original page to a separate journal file before modifying it. On crash, SQLite reads the journal and restores the original pages. This is simple but requires two writes for every modification—one to the journal, one to the database.
WAL mode inverts this relationship. Changes go to a separate WAL file, and the original database remains untouched. Readers can continue accessing the original data while writers append to the WAL. This eliminates the “database is locked” errors that plague concurrent SQLite usage.
But WAL mode introduces its own complexity. The WAL file grows until a checkpoint operation moves its contents back to the main database. If readers hold transactions open for extended periods, the checkpoint cannot proceed, and the WAL file grows without bound. A 1000-page default checkpoint threshold balances write performance against read performance—larger WAL files improve write throughput but slow reads as they must scan more of the log.
The fsync Problem
WAL’s durability guarantee rests on one fragile assumption: when the database calls fsync, the data actually reaches stable storage. This assumption is often violated.
Storage devices lie. Consumer-grade SSDs frequently acknowledge writes before they’re safely stored, buffering them in volatile cache to improve benchmark scores. Operating systems lie—Linux’s pdflush daemon may hold dirty pages for 30 seconds before writing them. File systems lie—ext4’s default data=ordered mode only guarantees metadata consistency, not data consistency.
Databases respond with increasingly paranoid configurations. PostgreSQL’s fsync parameter defaults to on, forcing an fsync for every WAL write. Setting it to off can improve performance by orders of magnitude—but risks losing committed transactions on crash. The synchronous_commit parameter offers a middle ground, allowing transactions to return before the WAL is flushed while still guaranteeing eventual durability.
The mathematical relationship is stark. If fsync takes 5 milliseconds and you commit 100 transactions per second, you’re spending half your time just waiting for disk acknowledgment. Group commit reduces this by batching multiple commits into a single fsync. But the fundamental tension remains: durability costs latency.
Checkpointing: Balancing Recovery Time Against Performance
If WAL records every change, the log grows indefinitely. Recovery would require replaying the entire history of the database. Checkpointing solves this by periodically establishing a known-good starting point for recovery.
A fuzzy checkpoint allows transactions to continue during the checkpoint process. The database writes a checkpoint record to the log, noting which dirty pages exist and which transactions are active. It then flushes those pages to disk in the background. The checkpoint isn’t “complete” until all relevant pages are written, but normal operations continue throughout.
The checkpoint frequency represents a tradeoff. Frequent checkpoints reduce recovery time—there’s less log to replay. But checkpointing requires writing dirty pages to disk, competing with normal I/O. PostgreSQL’s checkpoint_timeout (default 5 minutes) and max_wal_size (default 1 GB) control this balance.
When recovery begins, the database reads the last checkpoint record to determine where to start analysis. Everything before that checkpoint is already reflected in the data files. Only log records after the checkpoint need consideration.
What WAL Cannot Protect Against
WAL guarantees that committed transactions survive crashes. It does not guarantee protection against all failures.
Media failure: If the disk itself fails, the WAL goes with it. This is why production databases use RAID, replication, or both. PostgreSQL’s continuous archiving sends WAL files to a separate storage system, enabling point-in-time recovery from backups.
Correlated failures: If both primary and replica fail simultaneously, WAL replication offers no protection. Geographic distribution and immutable backups become essential.
Application-level errors: WAL faithfully records whatever the application writes. If the application commits a DELETE that removes the wrong rows, WAL ensures that deletion is durable. Point-in-time recovery to a state before the error remains the only remedy.
The Enduring Insight
Jim Gray’s fundamental insight was recognizing that the problem of durability is really a problem of ordering. By ensuring that log records precede data pages, the database transforms a random-access write pattern into a sequential one. Sequential writes are faster, more reliable, and easier to recover.
Every major database—PostgreSQL, MySQL, Oracle, SQL Server, MongoDB, Kafka—implements some variant of Write-Ahead Logging. Netflix built a distributed WAL to solve cross-region replication and data durability across diverse storage systems. The pattern repeats because the problem it solves is fundamental: how do you maintain consistency in a world where failures are inevitable?
The next time you see a commit return in milliseconds, remember what’s actually happened. The data is probably still in memory. The disk hasn’t seen the changes. But a tiny log record sits safely on stable storage, waiting to replay your transaction if anything goes wrong. That’s the WAL at work: the invisible protocol that makes reliable computing possible.
References
-
Mohan, C., et al. “ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging.” ACM Transactions on Database Systems, 1992. https://web.stanford.edu/class/cs345d-01/rl/aries.pdf
-
PostgreSQL Documentation. “Write-Ahead Logging (WAL).” PostgreSQL 18 Documentation. https://www.postgresql.org/docs/current/wal-intro.html
-
Gray, J. “The Transaction Concept: Virtues and Limitations.” 1981. https://jimgray.azurewebsites.net/papers/thetransactionconcept.pdf
-
SQLite Documentation. “Write-Ahead Logging.” https://sqlite.org/wal.html
-
MySQL Reference Manual. “InnoDB Redo Log.” MySQL 9.0 Documentation. https://dev.mysql.com/doc/refman/9.0/en/innodb-redo-log.html
-
Karumanchi, P., et al. “Building a Resilient Data Platform with Write-Ahead Log at Netflix.” Netflix Technology Blog, 2025. https://netflixtechblog.com/building-a-resilient-data-platform-with-write-ahead-log-at-netflix-127b6712359a
-
CMU 15-445 Course Notes. “Database Crash Recovery.” Carnegie Mellon University. https://15445.courses.cs.cmu.edu/fall2024/notes/21-recovery.pdf
-
Sookocheff, K. “Write-ahead logging and the ARIES crash recovery algorithm.” 2022. https://sookocheff.com/post/databases/write-ahead-logging/