In 1984, researchers at the University of Illinois published a paper that would quietly shape every multicore processor built since. Mark Papamarcos and Janak Patel proposed a solution to a problem that didn’t seem urgent at the time—how to keep data consistent when multiple processors each have their own cache. Today, with CPUs packing dozens of cores, their invention runs on billions of devices, silently orchestrating a dance of state transitions every time one core writes to memory and another needs to read it.
The protocol is called MESI, named after its four states: Modified, Exclusive, Shared, and Invalid. It’s the invisible layer that makes shared-memory multiprocessing work. Without it, the code you write would produce completely unpredictable results when run across multiple threads.
The Problem: When Caches Lie
Modern CPUs don’t access main memory directly for every operation. That would be far too slow—DRAM access latency is typically 50-100 nanoseconds, while L1 cache access takes about 1-4 nanoseconds. To bridge this gap, each core maintains its own cache hierarchy: private L1 and L2 caches, often with a shared L3 cache.
This architecture creates a fundamental problem. Consider what happens when two cores cache the same memory location:
- Core A reads variable
x(value: 10) into its cache - Core B reads the same variable
xinto its cache - Core A writes
x = 20 - Core B reads
xfrom its cache and sees… 10
Core B’s cache is now lying. It holds a stale value that doesn’t reflect the current state of the system. This is the cache coherence problem, and without a protocol to solve it, multicore processors would be nearly useless for any program that shares data.
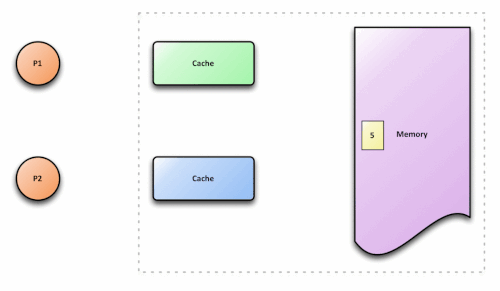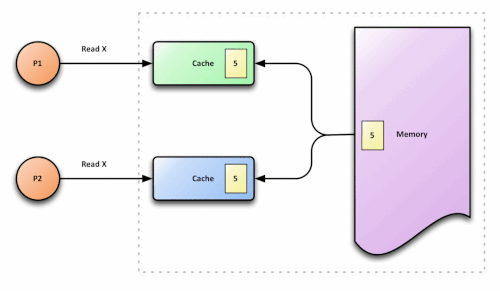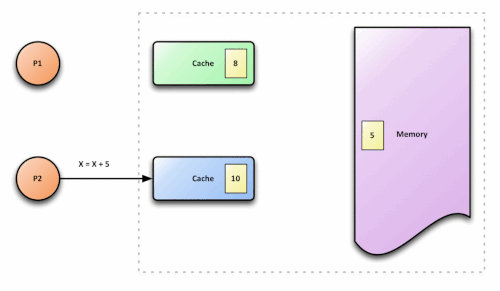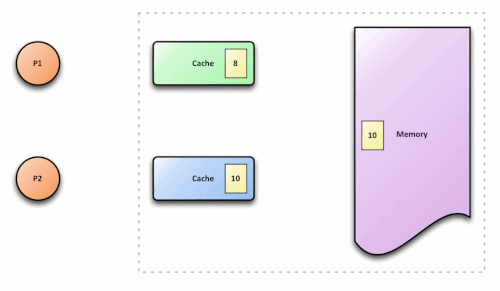
Image source: Wikipedia - Cache coherence
The MESI Solution: Four States, One Goal
The MESI protocol tracks the state of every cache line (typically 64 bytes on modern x86 processors) using two additional bits. Each cache line can be in exactly one of four states:
Modified (M): The cache line exists only in this cache and has been modified from the value in main memory. This cache is responsible for writing the data back to memory before any other processor can access it.
Exclusive (E): The cache line exists only in this cache and is clean—it matches main memory. The owning core can modify it without notifying anyone else.
Shared (S): The cache line may exist in multiple caches and is clean. Any cache holding this line can read from it freely, but writing requires coordination.
Invalid (I): The cache line is not present or doesn’t contain valid data.
The key insight behind MESI is the Exclusive state. Earlier protocols like MSI (Modified, Shared, Invalid) required every write to broadcast an invalidation message, even when no other core had a copy. The E state eliminates this overhead for the common case where a single core reads and then modifies data that no one else is using.
How It Works: A Step-by-Step Example
Let’s walk through what happens when three processors share a cache line. Initially, all caches are empty.
Step 1: Core 1 reads variable x
Core 1 issues a BusRd (bus read) request. No other cache has this line, so main memory supplies it. Core 1 places the line in Exclusive state—a prediction that no one else will need it.
Step 2: Core 1 writes to x
Since Core 1 holds the line in Exclusive state, it can modify it without any bus transaction. The line transitions to Modified. No other cores know this happened yet.
Step 3: Core 3 reads x
Core 3 issues a BusRd. Core 1’s snooper detects this request for a line it holds in Modified state. Core 1 must intervene: it supplies the updated data directly to Core 3 (a cache-to-cache transfer, faster than going to memory), writes back to main memory, and both cores now hold the line in Shared state.
Step 4: Core 3 writes to x
Core 3 has the line in Shared state, so it must invalidate other copies before writing. It broadcasts BusUpgr (bus upgrade). Core 1’s snooper sees this and invalidates its copy. Core 3’s line transitions to Modified.
Step 5: Core 1 reads x again
Core 1 issues BusRd. Core 3 supplies the modified data, transitions to Shared, and Core 1 receives it in Shared state.
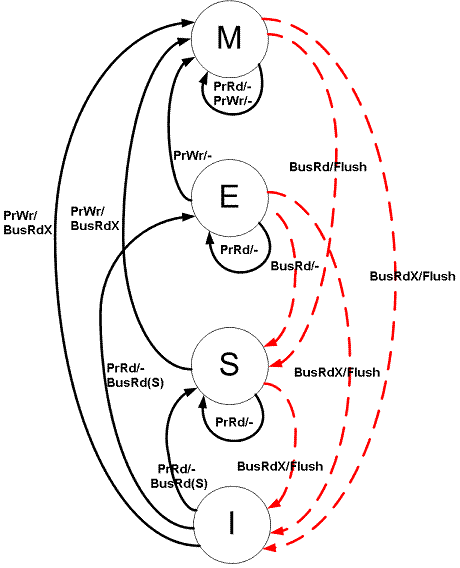
Image source: Wikipedia - MESI protocol
The Performance Killer: False Sharing
Understanding MESI reveals a subtle but devastating performance problem: false sharing. Consider two threads incrementing separate variables that happen to reside on the same cache line:
struct Counters {
std::atomic<int> counter1; // Thread A increments this
std::atomic<int> counter2; // Thread B increments this
};
Even though the threads never access the same variable, they’re fighting over the same cache line. Every write by Thread A invalidates the cache line in Thread B’s cache, forcing expensive cache-to-cache transfers. The MESI protocol dutifully maintains coherence, but at enormous cost.
Real-world benchmarks show this can degrade performance by 5x to 20x compared to properly aligned data. On a Zen4 system with 16 cores, incrementing a byte on a shared cache line can take up to 100 nanoseconds (roughly 420 clock cycles), compared to about 1 nanosecond when each variable has its own cache line.
The fix is cache line padding—ensuring frequently-modified variables from different threads don’t share a cache line:
struct alignas(64) PaddedCounter {
std::atomic<int> counter;
};
Java provides the @Contended annotation for this purpose. The JDK’s LongAdder class uses it internally, which is why copying its code without enabling the annotation (-XX:-RestrictContended) results in dramatically worse performance—around 360% lower throughput in benchmarks.
Store Buffers and the Memory Ordering Complication
A naive MESI implementation would stall the processor every time it needed to write to a line in Shared or Invalid state. Modern CPUs avoid this with store buffers—holding pending writes while the cache coherence machinery fetches the necessary permissions.
This optimization has profound implications for memory ordering. A core can read its own pending writes from its store buffer, but other cores can’t see them until they’re flushed to the cache. This creates the possibility of seeing different memory states from different cores—phenomena like “store buffering” that break naive assumptions about program order.
Memory barriers (fences) exist primarily to manage these store buffers and their counterparts, invalidation queues. A store barrier flushes the store buffer; a read barrier drains the invalidation queue. Without explicit barriers, reordering can occur, and lock-free algorithms become extremely difficult to implement correctly.
Beyond MESI: MOESI, MESIF, and Modern Extensions
MESI isn’t the final word on cache coherence. Its main weakness appears when multiple cores repeatedly read and write the same line: the data must be flushed to memory on every transition from Modified to Shared.
MOESI (used by AMD) adds an Owned state. A cache in Owned state can supply data to other cores without writing back to memory, reducing memory bandwidth consumption. The owner is responsible for eventually writing back.
MESIF (developed by Intel) adds a Forward state. When multiple caches hold a line in Shared state, exactly one is designated Forward and is responsible for responding to read requests. This eliminates redundant responses when multiple caches could supply the same data.
These extensions trade protocol complexity for better performance in specific sharing patterns—particularly important in NUMA (Non-Uniform Memory Access) systems where inter-socket communication latency can reach hundreds of nanoseconds.
Directory-Based Protocols: Scaling Beyond the Bus
Snooping protocols like MESI work well for systems with a shared bus, but they don’t scale. Broadcasting every coherence request to all cores wastes bandwidth as core counts increase.
Directory-based protocols solve this by maintaining a central directory that tracks which caches hold each memory block. Instead of broadcasting, a core queries the directory, which then contacts only the relevant caches. This scales to hundreds or thousands of cores but adds latency—the three-hop request/forward/respond pattern takes longer than a simple snoop.
Modern high-end servers typically use hybrid approaches, with directory-based protocols for inter-socket coherence and snooping within each socket’s local cache hierarchy.
Atomic Operations and Cache Coherence
The x86 LOCK prefix (used implicitly by atomic operations) interacts directly with cache coherence. When a CPU executes LOCK CMPXCHG, it doesn’t simply lock the bus—that would halt the entire system. Instead, it uses the cache coherence protocol to lock the specific cache line, ensuring atomicity for that line only.
This works because MESI guarantees that only one cache can hold a line in Modified state. By acquiring the line in M state before performing the atomic operation, the CPU ensures no other core can interfere. Modern implementations are far more sophisticated, but the fundamental principle remains: atomic operations are built on cache coherence.
Measuring the Invisible
Cache coherence overhead is invisible to most profiling tools. Traditional CPU profilers show time spent in functions, not cycles wasted waiting for cache line transfers.
The Linux perf c2c (cache-to-cache) tool is specifically designed to detect false sharing by measuring cache coherence traffic. High “HITM” (Hit Modified) percentages indicate cores are frequently accessing lines that another core holds in Modified state—the signature of false sharing.
Core-to-core latency measurements reveal the real cost: transferring a cache line between two cores on the same socket typically takes 40-100 nanoseconds. Crossing socket boundaries in NUMA systems can take 150-300 nanoseconds. Compare this to L1 cache access at 1-4 nanoseconds, and the importance of cache-aware programming becomes clear.
When Coherence Fails: The Edge Cases
Cache coherence protocols make certain guarantees, but they’re not magic. A coherent system ensures that all cores eventually see writes to the same location in the same order, but it doesn’t guarantee when.
The distinction between coherence and consistency matters. Coherence concerns a single memory location; consistency concerns the entire memory system. A system can be cache-coherent but not sequentially consistent—MESI provides coherence, but the memory model (x86’s TSO, ARM’s weaker model) determines consistency.
Speculative execution attacks like Spectre exploit cache coherence side channels. By measuring how quickly a cache line can be accessed, an attacker can infer whether it’s cached—and therefore whether speculative execution touched certain memory locations. The timing differences created by MESI state transitions become an information leak.
The Takeaway
The MESI protocol is one of computing’s quiet triumphs. It solves a problem that becomes harder with every core added to a processor, and it does so with just four states and two bits per cache line. Every lock-free algorithm, every concurrent hash map, every high-performance database relies on it working correctly.
For developers, the lesson is practical: understand your data layout. The difference between two variables sharing a cache line versus living on separate lines can mean the difference between scaling linearly with core count and grinding to a halt. Cache coherence is free in terms of correctness—your program will produce the right answers—but expensive in terms of performance when used carelessly.
The next time you’re optimizing multithreaded code and performance plateaus despite high CPU utilization, remember: the problem might not be in your algorithm. It might be in your cache lines.
References
-
Papamarcos, M. S., & Patel, J. H. (1984). “A Low-Overhead Coherence Solution for Multiprocessors with Private Cache Memories.” Proceedings of the 11th Annual International Symposium on Computer Architecture, 348-354.
-
Sorin, D. J., Hill, M. D., & Wood, D. A. (2011). A Primer on Memory Consistency and Cache Coherence. Morgan & Claypool Publishers.
-
Culler, D. E., Singh, J. P., & Gupta, A. (1999). Parallel Computer Architecture: A Hardware-Software Approach. Morgan Kaufmann Publishers.
-
Intel Corporation. “Intel® 64 and IA-32 Architectures Software Developer’s Manual.” Volume 3, Chapter 11: Memory Cache Control.
-
AMD. “AMD64 Technology: Memory System (Memory Coherency and Protocol).” Publication 24592, Revision 3.11.
-
Bolosky, W. J., & Scott, M. L. (1993). “False Sharing and Its Effect on Shared Memory Performance.” USENIX Systems on USENIX Experiences with Distributed and Multiprocessor Systems, 4.
-
Chabbi, M., Wen, S., & Liu, X. (2018). “Featherlight On-the-fly False-sharing Detection.” Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 152-167.