A file sits on disk. Your application reads it and sends it over the network. Simple enough—but behind this mundane operation hides one of computing’s most persistent performance bottlenecks.
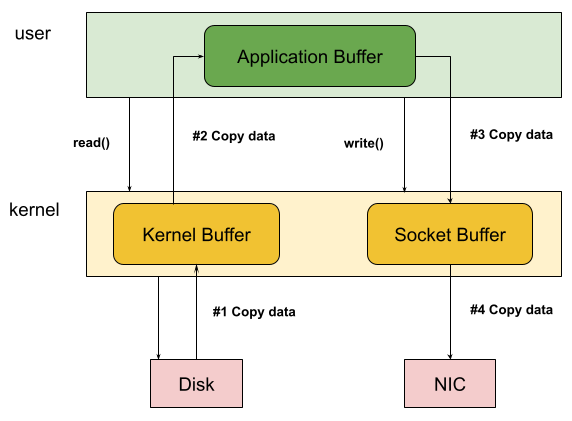
In a traditional I/O path, that single file traverses through four distinct memory copies before reaching the network interface. The kernel reads data from disk into a kernel buffer via DMA. The read() system call copies it to user space. The write() system call copies it back to a kernel socket buffer. Finally, DMA transfers it to the NIC. Each copy consumes CPU cycles, memory bandwidth, and cache space.
Zero-copy techniques promise to eliminate these redundant transfers. Yet many implementations that claim “zero-copy” status still perform hidden copies—sometimes right under your nose.
The Traditional Tax: Where Your CPU Cycles Go
Before dissecting zero-copy failures, let’s quantify the problem. When an application reads 1GB from disk and sends it over the network using traditional read() and write() calls:
Disk → Kernel Buffer (DMA)
Kernel Buffer → User Buffer (CPU copy)
User Buffer → Socket Buffer (CPU copy)
Socket Buffer → NIC (DMA)

Image source: DZone
{kind=link}
Two DMA transfers offload work to hardware, but the two CPU copies in the middle are pure overhead. Each copy requires the CPU to read data from memory, potentially missing cache, then write it back to a different location. For high-throughput systems—think Kafka brokers, video streaming servers, or CDN edge nodes—this overhead becomes the primary bottleneck.
The hidden cost multiplies under load. Consider a server handling 10,000 concurrent connections, each transferring 1MB/sec. That’s 10GB/sec of actual data, but 20GB/sec of memory bandwidth consumed by copies alone. Modern DDR4 memory might sustain 25-50GB/sec, meaning nearly half your memory bandwidth vanishes into redundant data movement.
Zero-Copy’s Promise and Its Cracks
Linux provides several zero-copy mechanisms: sendfile(), splice(), tee(), vmsplice(), MSG_ZEROCOPY, and the newer io_uring zero-copy operations. Each has specific constraints that can silently reintroduce copies.
sendfile(): The Original, With Limitations
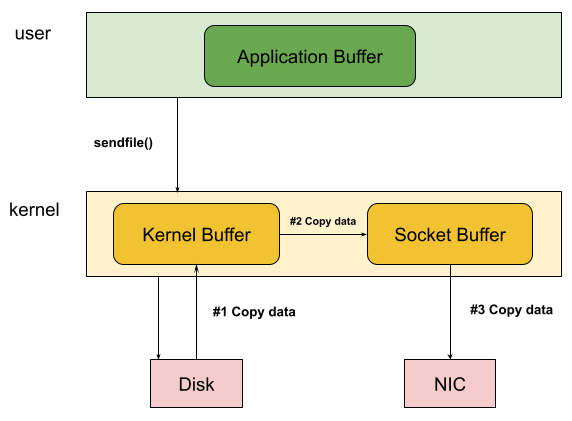
The sendfile() system call transfers data directly from a file descriptor to a socket without crossing into user space:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
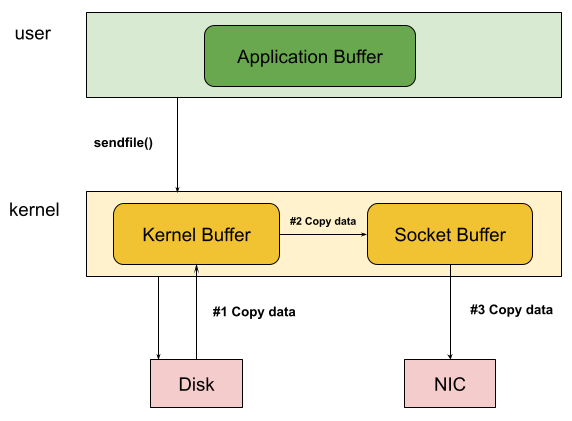
Image source: DZone
{kind=link}
This reduces the four-copy path to two DMA transfers. But sendfile() has a critical limitation: it only works when the source is a regular file and the destination is a socket. Want to splice data between two sockets? Forward traffic from one network connection to another? sendfile() cannot help.
More insidiously, sendfile() may still copy data in certain conditions. If the file isn’t in the page cache, the kernel reads it from disk—but if checksum offloading isn’t supported by the NIC, the kernel must compute checksums by reading through the data. At that point, copying becomes nearly free since the data is already in cache.
splice(): The Generalization That Revealed The Truth
Linus Torvalds designed splice() as sendfile()’s more capable successor. The key insight? A pipe is the universal in-kernel buffer:
“The pipe is the buffer. The reason sendfile() sucks is that sendfile cannot work with
different buffer representations. sendfile() only works with one buffer representation, namely the ‘page cache of the file’.” — Linus Torvalds, 2006
splice() moves data between arbitrary file descriptors by using a pipe as an intermediary buffer. But here’s the catch: one of the file descriptors must be a pipe. When splicing between two non-pipe descriptors, you must create an intermediate pipe, introducing a conceptual “copy” of buffer references—even if the actual data isn’t copied.
The vmsplice() variant attempts zero-copy from user memory to a pipe, but it requires the application to not modify the buffer until the kernel indicates completion. Modify the buffer prematurely? Data corruption. This makes vmsplice() unsuitable for many patterns where data is generated dynamically.
MSG_ZEROCOPY: The Modern Approach With Hidden Thresholds
Linux 4.14 introduced MSG_ZEROCOPY, extending zero-copy to regular socket send() calls:
setsockopt(socket, SOL_SOCKET, SO_ZEROCOPY, &opt, sizeof(opt));
send(socket, buffer, length, MSG_ZEROCOPY);
This looks perfect—send arbitrary user-space data without copying. But the kernel documentation reveals a crucial detail:
“Due to the overhead associated with pinning down pages, MSG_ZEROCOPY is generally only effective at writes larger than 10 KB.”
Below that threshold, the cost of pinning pages in memory (required to prevent swapping during DMA) exceeds the cost of simply copying the data. Your “zero-copy” operation silently falls back to copying, and you might never notice.
The notification mechanism also adds complexity. Since send() returns before transmission completes, the application must read completion notifications from the socket’s error queue:
recvmsg(socket, &message, MSG_ERRORQUEUE);
Miss this step and you’ll reuse buffers prematurely, corrupting in-flight data.
mmap(): Zero-Copy or Zero-Guarantee?
Memory-mapped files seem like the ultimate zero-copy technique—map a file directly into your address space and access it like memory:
void *data = mmap(NULL, size, PROT_READ, MAP_PRIVATE, fd, 0);
The operating system loads file pages on demand, and reads/writes go directly to the page cache. But three hidden costs lurk:
Page fault overhead: Each first access to a page triggers a page fault. The kernel must locate the page, possibly read it from disk, and update page tables. For random access patterns, this overhead can exceed the cost of a simple read() call that brings pages in sequentially.
Copy-on-write semantics: MAP_PRIVATE mappings use copy-on-write. Write to the mapped region, and the kernel copies the underlying page before modification. What started as zero-copy suddenly isn’t.
Cache pressure: Mapped pages compete for cache space with other memory. A process that mmaps a 10GB file but only reads 100MB may still evict useful cache lines from the page cache, harming overall system performance.
Research from USENIX demonstrates that for memory-mapped file systems, page fault overhead can consume up to 11% of total access time—hardly “free” access.
DMA: The Hardware Reality Check
Direct Memory Access offloads data movement to specialized hardware, freeing the CPU from byte-shuffling drudgery. But DMA requires physically contiguous memory—a rarity in systems that have been running for days.
When you call cudaMemcpy() to transfer data to a GPU, here’s what actually happens:
- If the source is pageable memory, CUDA first copies it to a temporary pinned buffer
- DMA then transfers from the pinned buffer to GPU memory
That “zero-copy” transfer actually involved a copy you didn’t request. Using cudaHostAlloc() to allocate pinned memory from the start avoids this, but pinned memory is a scarce resource—over-allocate and you’ll starve the kernel.
The PCIe bus also imposes overhead. Each DMA transfer requires descriptor setup, arbitration, and completion handling. For small transfers, this overhead dominates. Benchmarks show that GPU transfers under 64KB achieve far lower throughput than larger transfers—precisely because the setup overhead amortizes poorly.
When “Zero-Copy” Becomes A Lie
Several scenarios guarantee your zero-copy attempt will degrade:
Checksum offloading disabled: If your NIC can’t compute TCP checksums, the kernel must read every byte anyway. At that point, copying is essentially free—the data is already in cache.
IPSec or TLS: Encrypted tunnels require the kernel to transform data. Transformation requires reading and writing, so copies become unavoidable. This is why high-performance VPNs often terminate encryption in user space with libraries like DPDK.
Virtualization: Virtual machines add another layer of address translation. Shadow page tables or Extended Page Tables (EPT) introduce translation overhead for every memory access. Data that crosses between guest and host—like network packets processed by a virtual NIC—often gets copied during the transition.
Small messages: Below roughly 10KB, the overhead of setting up zero-copy (pinning pages, managing completion notifications, handling error paths) exceeds the cost of a simple memcpy(). Sophisticated systems like Netty now implement adaptive thresholds, only using zero-copy for buffers exceeding the crossover point.
The Performance Reality: Benchmarks Don’t Lie
Comparisons between traditional I/O and zero-copy show consistent patterns. A simple benchmark transferring 100MB over localhost:
| Method | Transfer Time | Throughput |
|---|---|---|
| Traditional read/write | 0.204 seconds | 490 MB/s |
| Zero-copy sendfile() | 0.144 seconds | 695 MB/s |
A 40% improvement—significant, but not the orders-of-magnitude gains often promised. The real-world production improvements cited by kernel developers for MSG_ZEROCOPY range from 5-8% for realistic workloads to 39% for synthetic benchmarks.
The message is clear: zero-copy helps, but it’s not magic. The gains scale with message size and depend heavily on hardware support.
Designing For Reality
Understanding where copies hide enables better design decisions:
Batch aggressively: Zero-copy benefits grow with message size. Accumulate small messages into larger batches before transmission.
Use appropriate APIs for the job: sendfile() for file-to-socket transfers. splice() for socket-to-socket forwarding. io_uring with registered buffers for high-frequency small operations.
Profile before optimizing: Memory bandwidth might not be your bottleneck. Amdahl’s Law applies—optimize what actually limits your performance.
Consider the whole stack: Your application might use zero-copy, but what about your serialization format? FlatBuffers can be accessed without parsing, but Protocol Buffers require materialization. A zero-copy network transfer followed by a deserialization copy defeats the purpose.
Zero-copy remains valuable for high-throughput systems. Just remember: “zero” is an aspiration, not a guarantee. Every abstraction leaks, and in the case of I/O, the leaks manifest as unexpected memory copies.
References
- Willem de Bruijn, “MSG_ZEROCOPY: The Linux Kernel Documentation”, https://docs.kernel.org/networking/msg_zerocopy.html
- Linus Torvalds, “Re: [PATCH] splice support #2”, Linux Kernel Mailing List, March 2006, https://yarchive.net/comp/linux/splice.html
- Jonathan Corbet, “Zero-copy networking”, LWN.net, July 2017, https://lwn.net/Articles/726917/
- IBM Developer, “Java ZeroCopy I/O optimization for high throughput networking”, https://developer.ibm.com/articles/j-zerocopy/
- NVIDIA Developer, “How to Optimize Data Transfers in CUDA C/C++”, https://developer.nvidia.com/blog/how-optimize-data-transfers-cuda-cc/
- USENIX, “Efficient Memory Mapped File I/O for In-Memory File Systems”, https://www.usenix.org/system/files/conference/hotstorage17/hotstorage17-paper-choi.pdf
- man7.org, “sendfile(2) - Linux manual page”, https://man7.org/linux/man-pages/man2/sendfile.2.html
- man7.org, “vmsplice(2) - Linux manual page”, https://man7.org/linux/man-pages/man2/vmsplice.2.html